


整體跟蹤分析導論¶
建立日期:2024 年 1 月 2 日 | 最後更新:2024 年 1 月 5 日 | 最後驗證:2024 年 11 月 5 日
作者: Anupam Bhatnagar
在本教程中,我們將演示如何使用整體跟蹤分析 (HTA) 來分析分散式訓練作業的跟蹤。請按照以下步驟開始。
安裝 HTA¶
我們推薦使用 Conda 環境安裝 HTA。要安裝 Anaconda,請參閱Anaconda 官方文件。
使用 pip 安裝 HTA
pip install HolisticTraceAnalysis
(可選且推薦) 設定 Conda 環境
# create the environment env_name conda create -n env_name # activate the environment conda activate env_name # When you are done, deactivate the environment by running ``conda deactivate``
開始¶
啟動 Jupyter notebook 並將 trace_dir 變數設定為跟蹤檔案所在的路徑。
from hta.trace_analysis import TraceAnalysis
trace_dir = "/path/to/folder/with/traces"
analyzer = TraceAnalysis(trace_dir=trace_dir)
時間分解¶
為了有效利用 GPU,瞭解它們在特定作業上花費時間的方式至關重要。它們主要用於計算、通訊、記憶體事件,還是處於空閒狀態?時間分解功能詳細分析了在這三個類別中花費的時間。
空閒時間 - GPU 處於空閒狀態。
計算時間 - GPU 用於矩陣乘法或向量運算。
非計算時間 - GPU 用於通訊或記憶體事件。
為了實現高訓練效率,程式碼應最大化計算時間,最小化空閒時間和非計算時間。以下函式生成一個 dataframe,詳細列出了每個 rank 的時間使用分解。
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
time_spent_df = analyzer.get_temporal_breakdown()
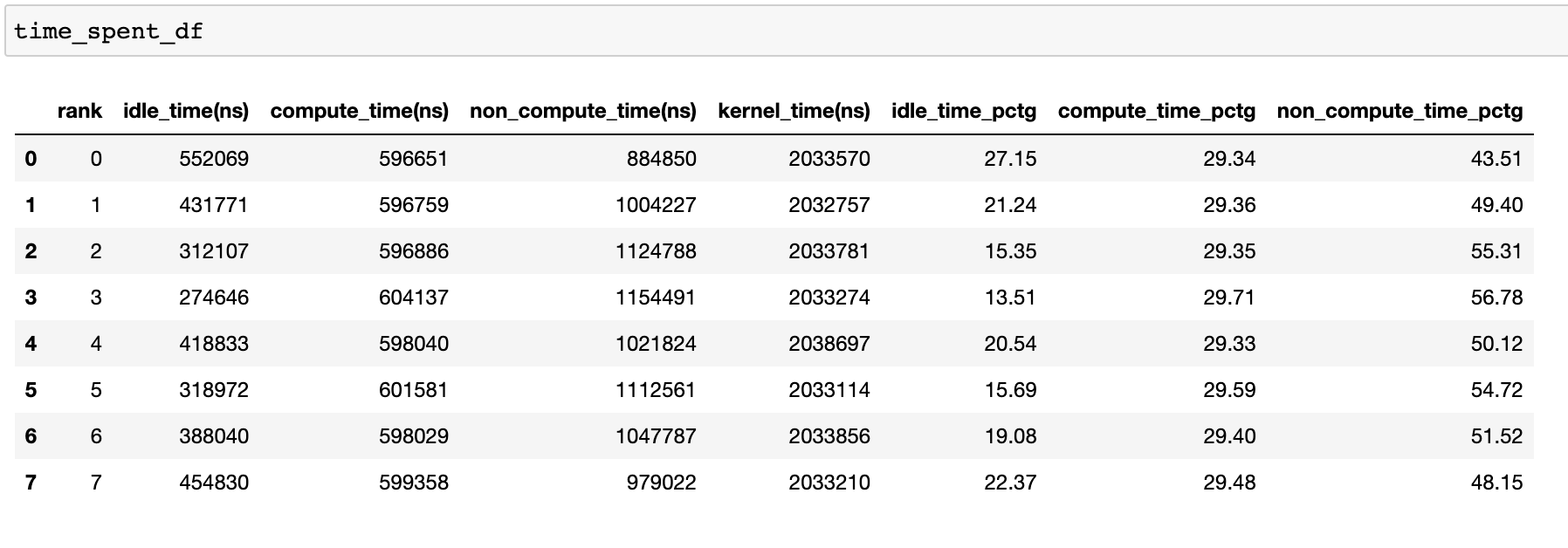
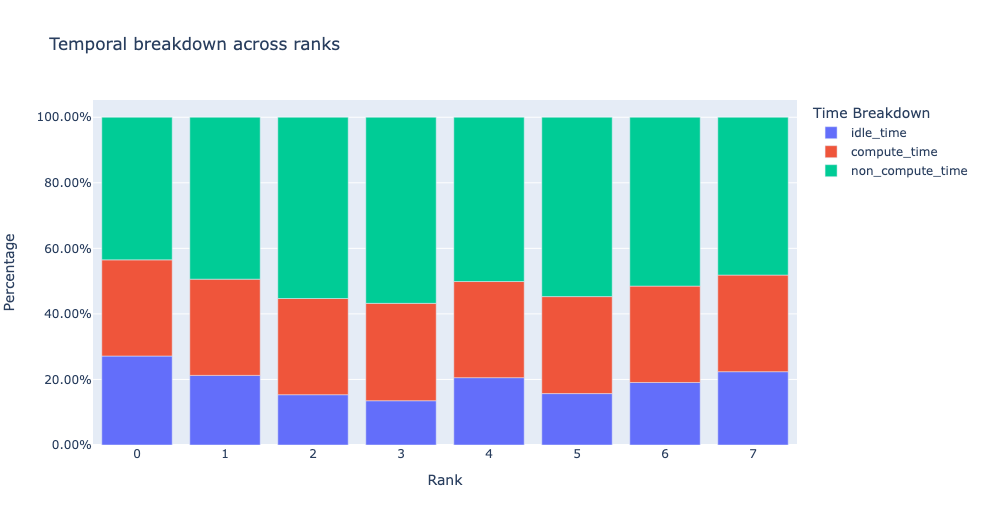
當 get_temporal_breakdown 函式中的 visualize 引數設定為 True 時,它還會生成一個按 rank 分解的條形圖。
空閒時間分解¶
瞭解 GPU 空閒的時間量及其原因有助於指導最佳化策略。當 GPU 上沒有執行核心時,它被認為是空閒的。我們開發了一種演算法,將空閒時間分為三個不同的類別
Host 等待: 指的是 GPU 上的空閒時間,這是由於 CPU 入隊核心不夠快,無法使 GPU 得到充分利用。可以透過檢查導致速度變慢的 CPU 運算子、增加批處理大小和應用運算子融合來解決這些低效問題。
Kernel 等待: 這指的是在 GPU 上啟動連續核心時相關的短暫開銷。可以透過使用 CUDA Graph 最佳化來最小化歸因於此類別的空閒時間。
其他等待: 此類別包括當前無法歸因的空閒時間,原因可能是資訊不足。可能的原因包括使用 CUDA 事件在 CUDA 流之間同步以及啟動核心時的延遲。
Host 等待時間可以解釋為 GPU 由於 CPU 停頓的時間。要將空閒時間歸因於 Kernel 等待,我們使用以下啟發式方法
連續核心之間的間隔 < 閾值
預設閾值值為 30 納秒,可以使用 consecutive_kernel_delay 引數進行配置。預設情況下,空閒時間分解僅計算 rank 0。為了計算其他 rank 的分解,請使用 get_idle_time_breakdown 函式中的 ranks 引數。空閒時間分解可以按如下方式生成
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
idle_time_df = analyzer.get_idle_time_breakdown()
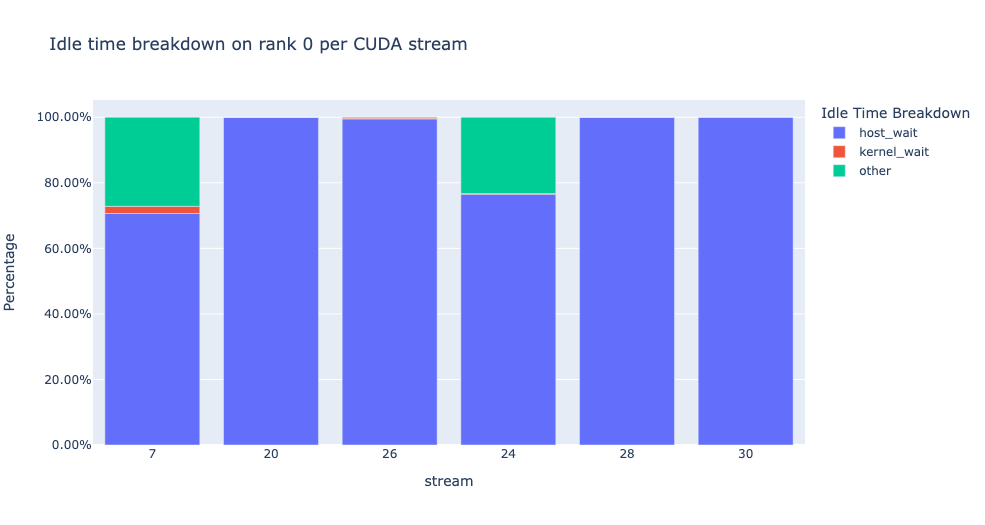
該函式返回一個 dataframe 元組。第一個 dataframe 包含每個 rank 在每個流上按類別劃分的空閒時間。
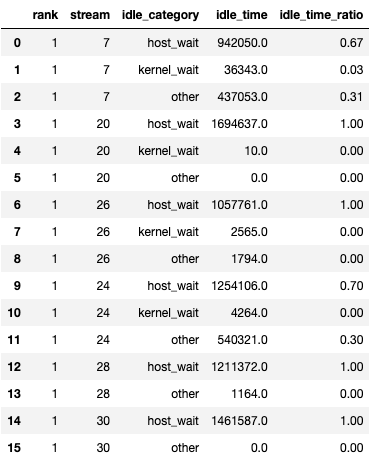
第二個 dataframe 在 show_idle_interval_stats 設定為 True 時生成。它包含每個 rank 在每個流上的空閒時間摘要統計資訊。
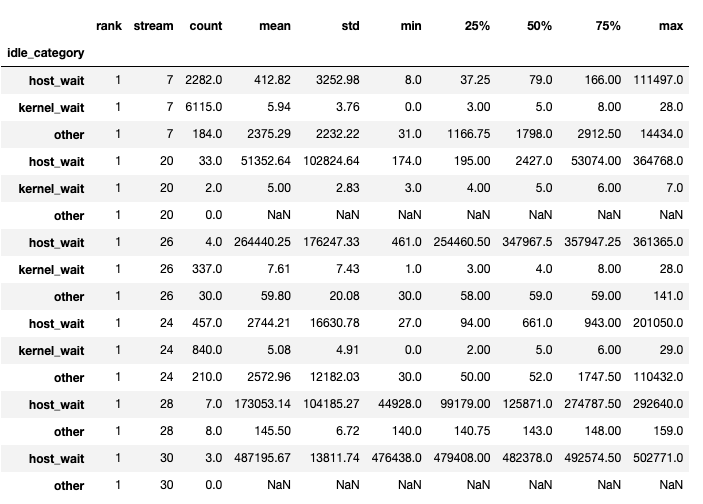
提示
預設情況下,空閒時間分解顯示每個空閒時間類別的百分比。將 visualize_pctg 引數設定為 False,函式將以絕對時間作為 Y 軸進行渲染。
Kernel 分解¶
Kernel 分解功能分解了每種核心型別(例如通訊 (COMM)、計算 (COMP) 和記憶體 (MEM))在所有 rank 上花費的時間,並顯示了在每個類別中花費的時間比例。這是每個類別所花費時間的百分比餅圖
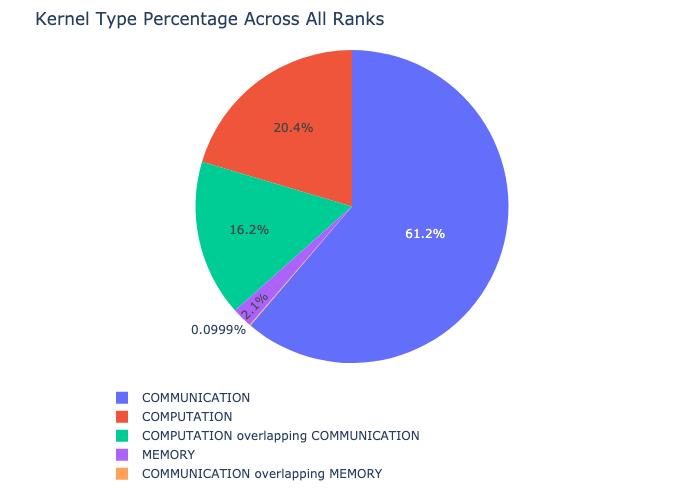
Kernel 分解可以按如下方式計算
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
kernel_type_metrics_df, kernel_metrics_df = analyzer.get_gpu_kernel_breakdown()
函式返回的第一個 dataframe 包含用於生成餅圖的原始值。
Kernel 持續時間分佈¶
get_gpu_kernel_breakdown 返回的第二個 dataframe 包含每個核心的持續時間摘要統計資訊。特別是,這包括每個 rank 上每個核心的計數、最小值、最大值、平均值、標準差、總和以及核心型別。
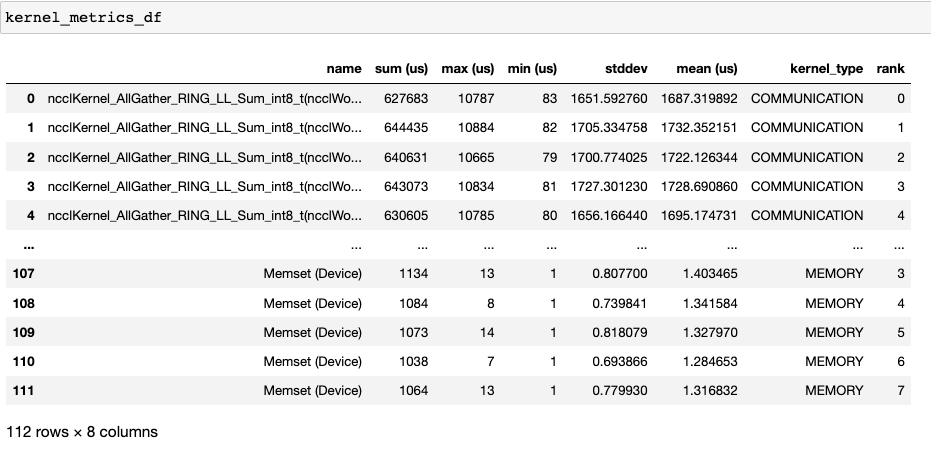
使用此資料,HTA 建立了許多視覺化圖來識別效能瓶頸。
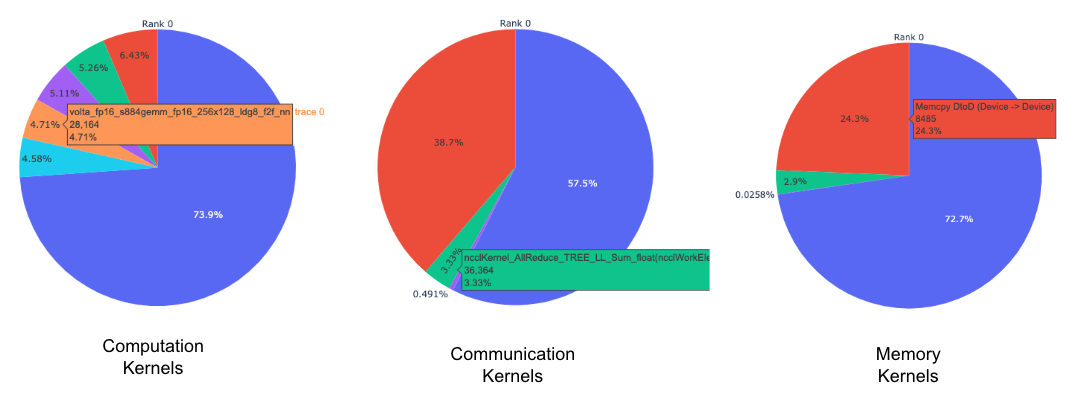
每個 rank 的每種核心型別的前 K 個核心的餅圖。
所有 rank 中每個 top kernel 和每種 kernel 型別的平均持續時間條形圖。
提示
所有影像均使用 plotly 生成。將滑鼠懸停在圖上會顯示右上角的模式欄,使用者可以縮放、平移、選擇和下載圖。
上面的餅圖顯示了前 5 個計算、通訊和記憶體核心。每個 rank 都生成了類似的餅圖。可以使用傳遞給 get_gpu_kernel_breakdown 函式的 num_kernels 引數配置餅圖以顯示前 k 個核心。此外,可以使用 duration_ratio 引數調整需要分析的時間百分比。如果同時指定了 num_kernels 和 duration_ratio,則 num_kernels 具有優先權。
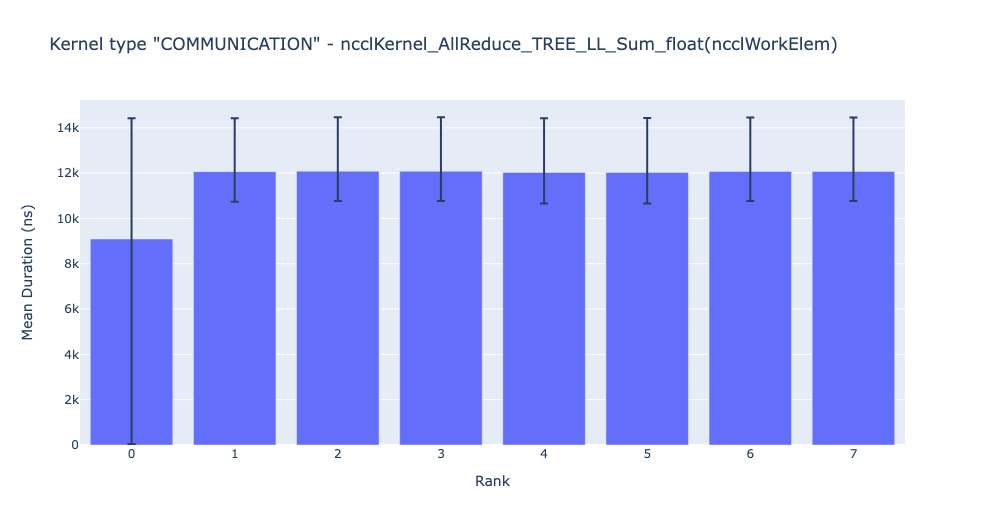
上面的條形圖顯示了 NCCL AllReduce 核心在所有 rank 中的平均持續時間。黑線表示每個 rank 花費的最小和最大時間。
警告
使用 jupyter-lab 時,將“image_renderer”引數值設定為“jupyterlab”,否則圖將無法在 notebook 中渲染。
有關此功能的詳細演練,請參閱倉庫 examples 資料夾中的 gpu_kernel_breakdown notebook。
通訊計算重疊¶
在分散式訓練中,大量時間花費在 GPU 之間的通訊和同步事件上。為了實現高 GPU 效率(例如 TFLOPS/GPU),關鍵在於透過計算核心保持 GPU 超負荷運轉。換句話說,GPU 不應因未解決的資料依賴而阻塞。衡量計算被資料依賴阻塞程度的一種方法是計算通訊計算重疊。如果通訊事件與計算事件重疊,則觀察到更高的 GPU 效率。通訊和計算重疊不足會導致 GPU 空閒,從而導致效率低下。總而言之,期望有更高的通訊計算重疊。為了計算每個 rank 的重疊百分比,我們測量以下比率
(通訊時花費在計算上的時間)/(花費在通訊上的時間)
通訊計算重疊可以按如下方式計算
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
overlap_df = analyzer.get_comm_comp_overlap()
該函式返回一個 dataframe,其中包含每個 rank 的重疊百分比。
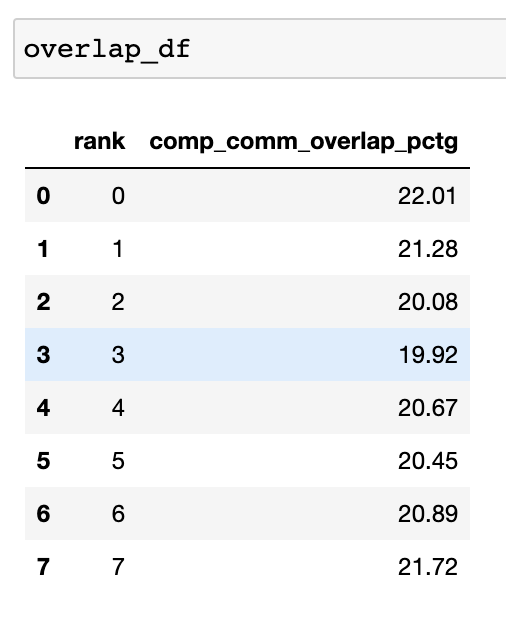
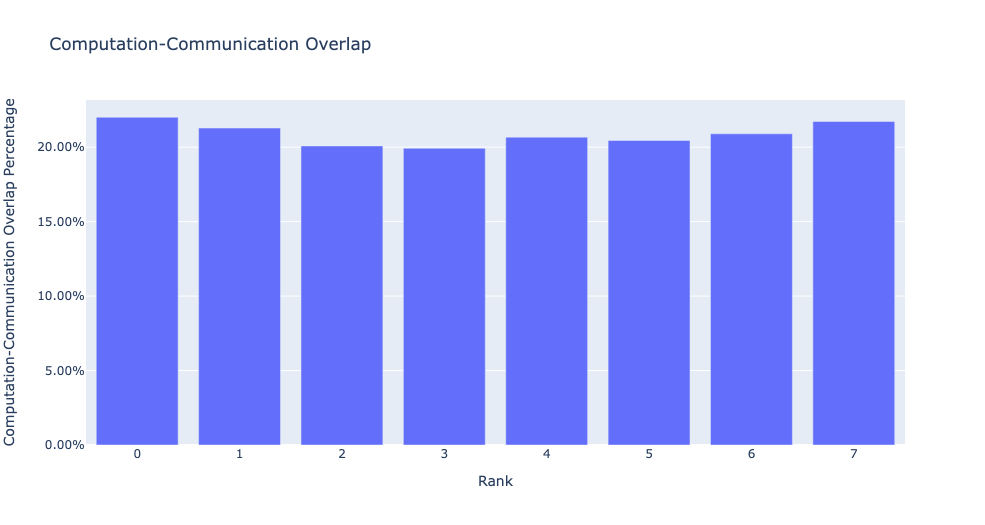
當 visualize 引數設定為 True 時,get_comm_comp_overlap 函式還會生成一個按 rank 表示重疊的條形圖。
增強計數器¶
記憶體頻寬和佇列長度計數器¶
記憶體頻寬計數器測量透過記憶體複製 (memcpy) 和記憶體設定 (memset) 事件在 H2D、D2H 和 D2D 之間複製資料時使用的記憶體複製頻寬。HTA 還計算每個 CUDA 流上的未完成運算元。我們將此稱為佇列長度。當流上的佇列長度達到 1024 或更大時,新事件無法在該流上排程,CPU 將停頓,直到 GPU 流上的事件處理完畢。
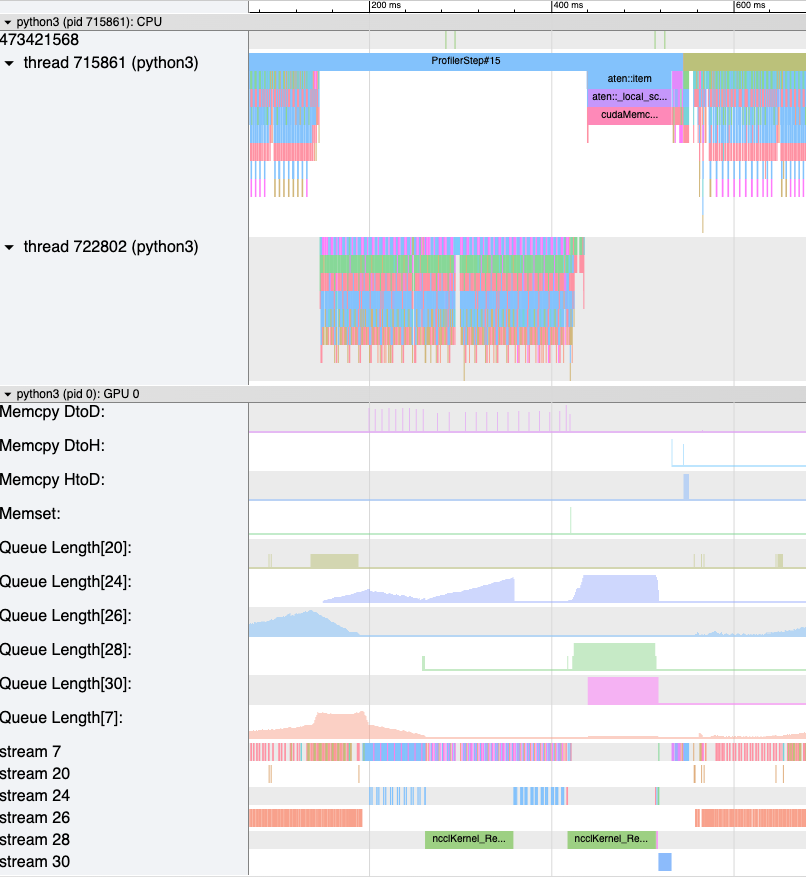
generate_trace_with_counters API 輸出一個帶有記憶體頻寬和佇列長度計數器的新跟蹤檔案。新跟蹤檔案包含指示 memcpy/memset 操作使用的記憶體頻寬的跟蹤以及每個流上佇列長度的跟蹤。預設情況下,這些計數器是使用 rank 0 的跟蹤檔案生成的,新檔案的名稱中包含字尾 _with_counters。使用者可以選擇使用 generate_trace_with_counters API 中的 ranks 引數為多個 rank 生成計數器。
analyzer = TraceAnalysis(trace_dir = "/path/to/trace/folder")
analyzer.generate_trace_with_counters()
生成的帶有增強計數器的跟蹤檔案截圖。
HTA 還使用以下 API 提供了記憶體複製頻寬和佇列長度計數器的摘要以及程式碼分析部分的計數器時間序列
要檢視摘要和時間序列,請使用
# generate summary
mem_bw_summary = analyzer.get_memory_bw_summary()
queue_len_summary = analyzer.get_queue_length_summary()
# get time series
mem_bw_series = analyzer.get_memory_bw_time_series()
queue_len_series = analyzer.get_queue_length_series()
摘要包含計數、最小值、最大值、平均值、標準差、第 25 百分位數、第 50 百分位數和第 75 百分位數。
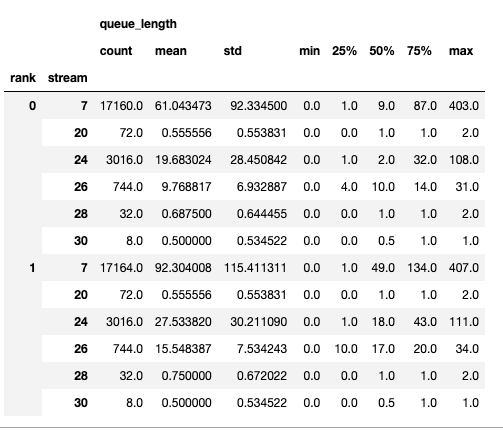
時間序列僅包含值發生變化的點。一旦觀察到值,時間序列將保持不變,直到下一次更新。記憶體頻寬和佇列長度時間序列函式返回一個字典,其鍵是 rank,值是該 rank 的時間序列。預設情況下,僅計算 rank 0 的時間序列。
CUDA Kernel 啟動統計資訊¶
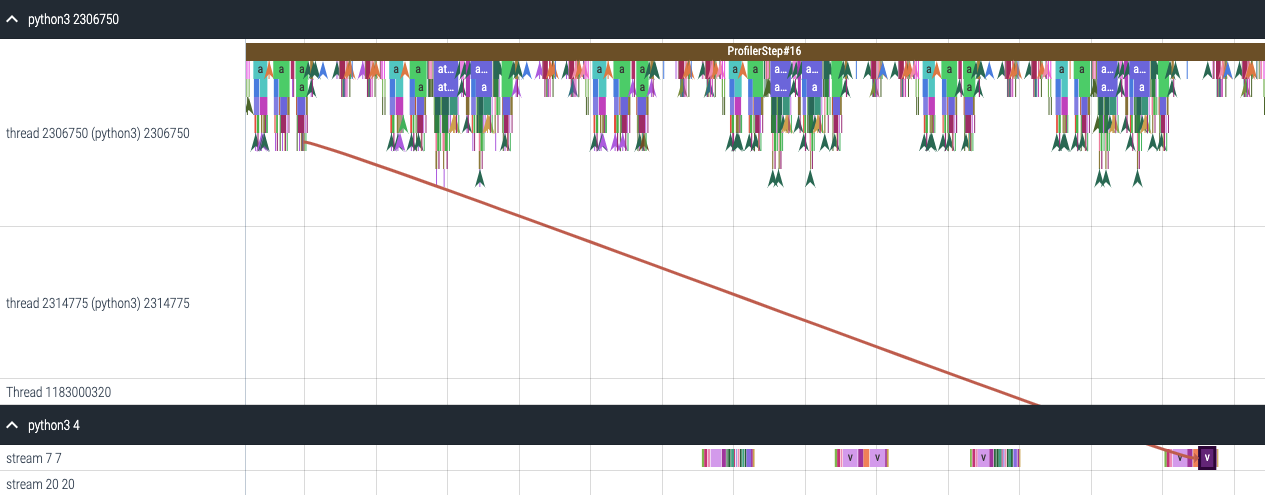
對於在 GPU 上啟動的每個事件,CPU 上都有相應的排程事件,例如 CudaLaunchKernel、CudaMemcpyAsync、CudaMemsetAsync。這些事件透過跟蹤中的公共相關 ID 連結在一起 - 參見上圖。此功能計算 CPU 執行時事件的持續時間、其對應的 GPU 核心以及啟動延遲,例如 GPU 核心啟動與 CPU 運算子結束之間的時間差。核心啟動資訊可以按如下方式生成
analyzer = TraceAnalysis(trace_dir="/path/to/trace/dir")
kernel_info_df = analyzer.get_cuda_kernel_launch_stats()
生成的 dataframe 截圖如下所示。
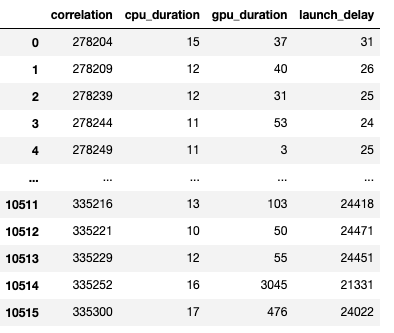
CPU 操作、GPU 核心和啟動延遲的持續時間使我們能夠發現以下情況
短 GPU 核心 - 持續時間小於相應 CPU 執行時事件的 GPU 核心。
執行時事件異常值 - 持續時間過長的 CPU 執行時事件。
啟動延遲異常值 - 需要很長時間才能被排程的 GPU 核心。
HTA 為上述三個類別中的每一個生成分佈圖。
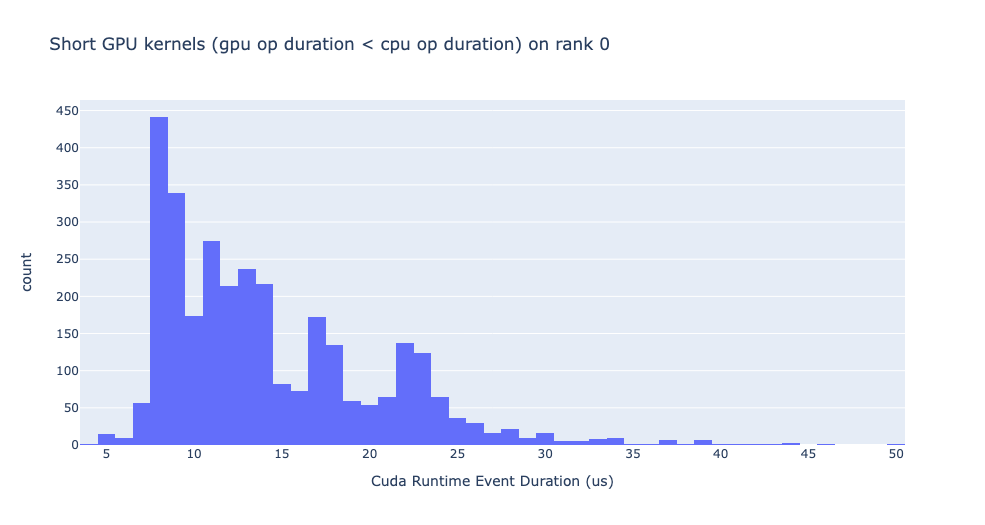
短 GPU 核心
通常,CPU 端的啟動時間範圍在 5-20 微秒。在某些情況下,GPU 執行時間低於啟動時間本身。下圖有助於我們瞭解程式碼中此類例項發生的頻率。
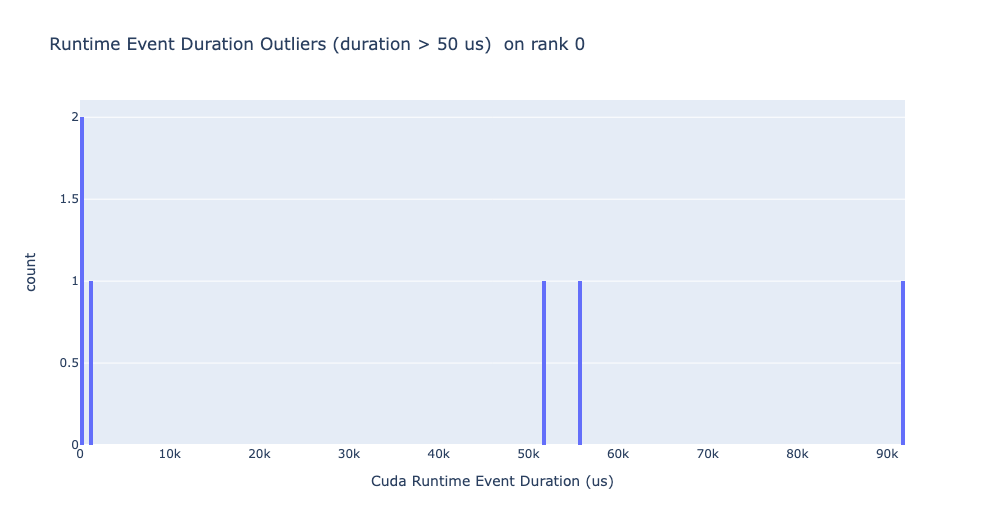
執行時事件異常值
執行時異常值取決於用於對異常值進行分類的截止值,因此 get_cuda_kernel_launch_stats API 提供了 runtime_cutoff 引數來配置該值。
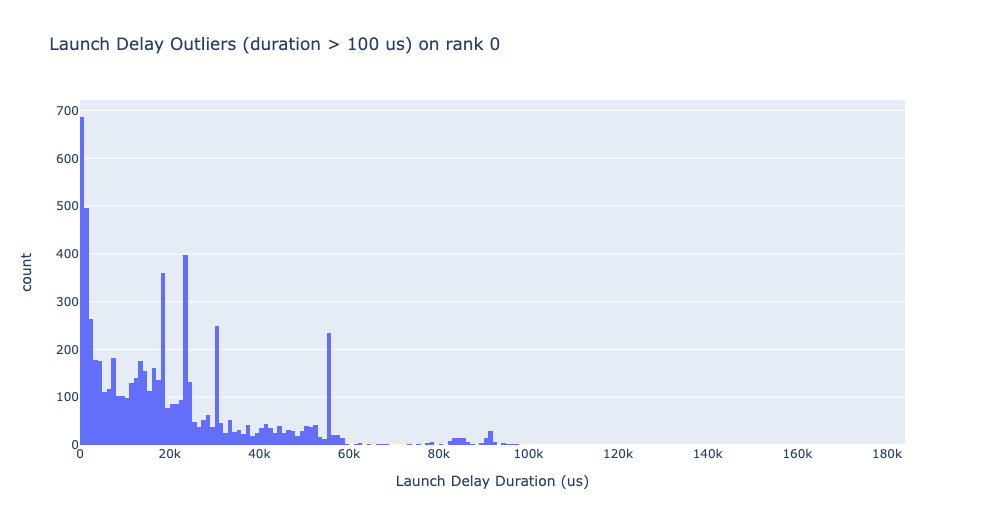
啟動延遲異常值
啟動延遲異常值取決於用於對異常值進行分類的截止值,因此 get_cuda_kernel_launch_stats API 提供了 launch_delay_cutoff 引數來配置該值。
結論¶
在本教程中,您學習瞭如何安裝和使用 HTA,這是一個性能工具,可幫助您分析分散式訓練工作流中的瓶頸。要了解如何使用 HTA 工具執行跟蹤對比分析,請參閱使用整體跟蹤分析進行跟蹤對比。
