


從第一性原理掌握 PyTorch Intel CPU 效能 (第二部分)¶
創建於: 2022 年 10 月 14 日 | 最後更新於: 2024 年 1 月 16 日 | 最後驗證: 未驗證
作者: Min Jean Cho, Jing Xu, Mark Saroufim
在從第一性原理掌握 PyTorch Intel CPU 效能教程中,我們介紹瞭如何調整 CPU 執行時配置、如何對其進行效能分析以及如何將它們整合到TorchServe 中以最佳化 CPU 效能。
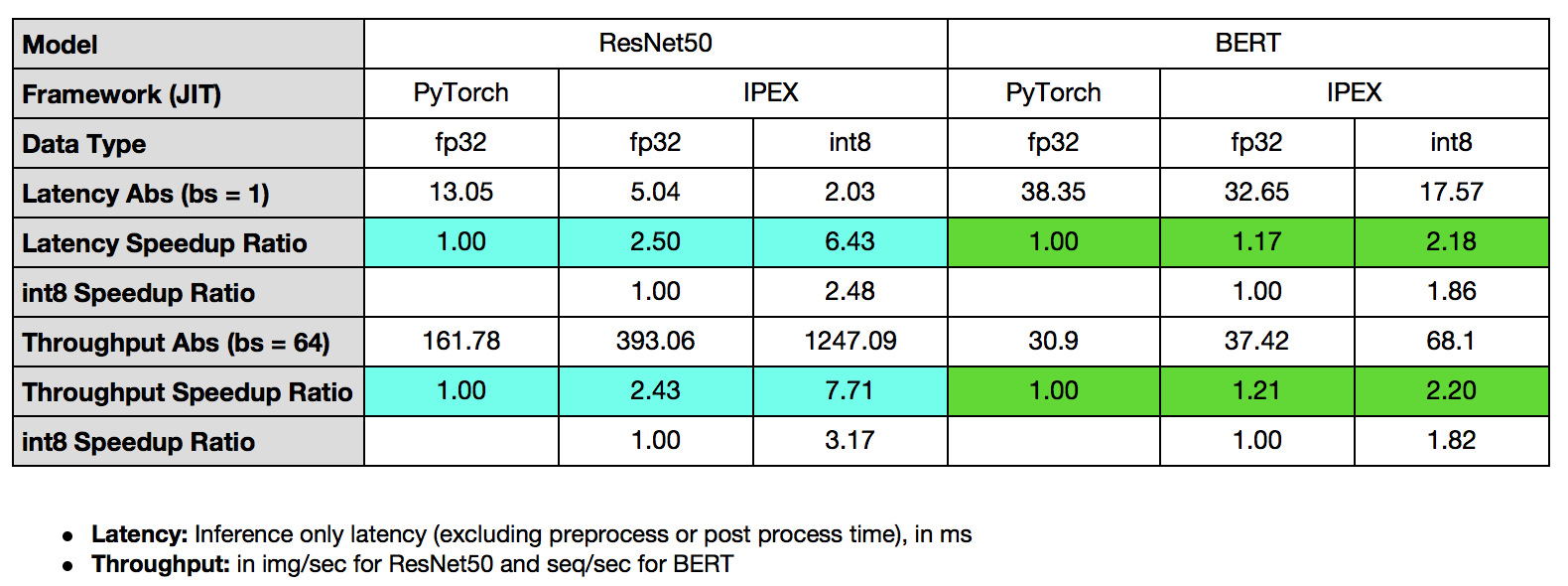
在本教程中,我們將演示如何透過Intel® Extension for PyTorch* Launcher 使用記憶體分配器提升效能,以及如何透過Intel® Extension for PyTorch* 在 CPU 上使用最佳化過的核心,並將這些技術應用於 TorchServe,展示 ResNet50 的吞吐量提速 7.71 倍,BERT 的吞吐量提速 2.20 倍。

先決條件¶
在本教程中,我們將使用自頂向下微架構分析 (TMA) 來分析並展示,對於未充分最佳化或未充分調優的深度學習工作負載,後端瓶頸 (記憶體瓶頸、核心瓶頸) 通常是主要的瓶頸,並演示如何透過 Intel® Extension for PyTorch* 改進後端瓶頸的最佳化技術。我們將使用 toplev,它是基於 Linux perf 構建的 pmu-tools 工具集的一部分,用於進行 TMA 分析。
我們還將使用Intel® VTune™ Profiler 的 instrumentation and Tracing Technology (ITT) 進行更細粒度的效能分析。
自頂向下微架構分析方法 (TMA)¶
在調優 CPU 以獲得最佳效能時,瞭解瓶頸所在非常有用。大多數 CPU 核心都帶有片上效能監控單元 (PMUs)。PMUs 是 CPU 核心內部專門的邏輯單元,用於計算系統上發生的特定硬體事件。這些事件的例子可能包括快取未命中或分支預測錯誤。PMUs 用於自頂向下微架構分析 (TMA) 以識別瓶頸。TMA 包含如下所示的分層級別
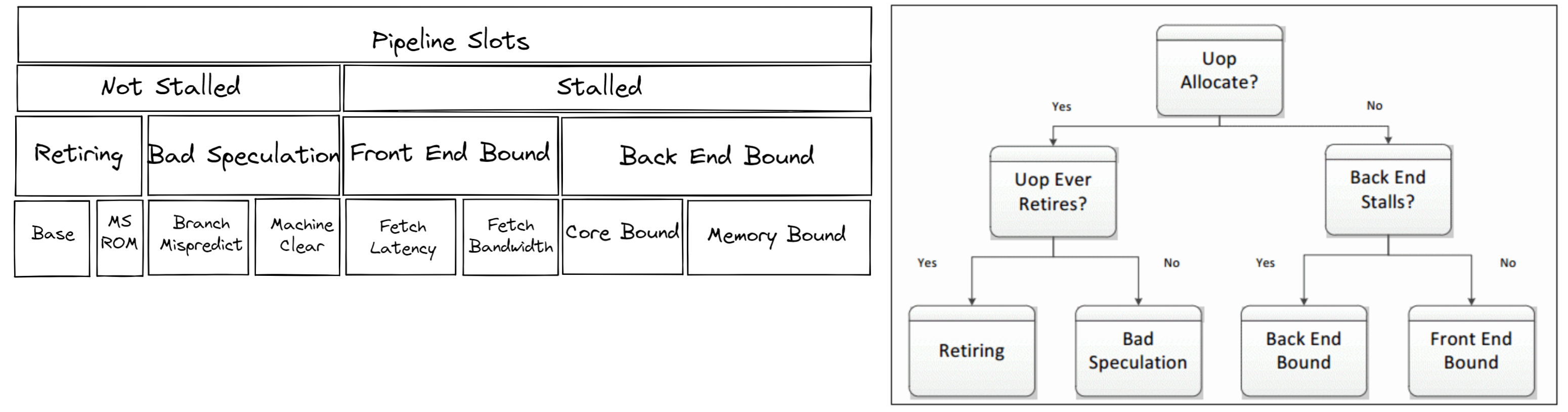
頂級指標,即 level-1 指標,收集 Retiring、Bad Speculation、Front End Bound、Back End Bound。CPU 的流水線概念上可以簡化分為兩部分:前端和後端。前端負責獲取程式程式碼並將其解碼為低階硬體操作,稱為微操作 (uOps)。然後,uOps 透過稱為分配的過程饋送到後端。一旦分配,後端負責在可用的執行單元中執行 uOp。uOp 執行的完成稱為 retirement。相反,bad speculation 是指推測獲取的 uOps 在退休前被取消,例如在分支預測錯誤的情況下。這些指標中的每一個都可以進一步分解到後續級別以精確定位瓶頸。
針對後端瓶頸進行調優¶
大多數未調優的深度學習工作負載都會受後端瓶頸限制。解決後端瓶頸通常是解決導致退休時間比必要時間更長的延遲源。如上所示,後端瓶頸有兩個子指標——核心瓶頸和記憶體瓶頸。
記憶體瓶頸停頓的原因與記憶體子系統有關。例如,最後一級快取(LLC 或 L3 快取)未命中導致訪問 DRAM。擴充套件深度學習模型通常需要大量的計算。高計算利用率要求在執行單元需要資料來執行微操作 (uOps) 時,資料是可用的。這需要預取資料並在快取中重用資料,而不是多次從主記憶體中獲取相同的資料,這會導致執行單元在資料返回時處於飢餓狀態。在本教程中,我們將展示,更高效的記憶體分配器、運算元融合、記憶體佈局格式最佳化可以減少記憶體瓶頸的開銷,並帶來更好的快取區域性性。
核心瓶頸停頓表明在沒有未完成的記憶體訪問時,對可用執行單元的使用未達到最佳狀態。例如,連續的多個通用矩陣乘法 (GEMM) 指令競爭融合乘加 (FMA) 或點積 (DP) 執行單元可能會導致核心瓶頸停頓。關鍵的深度學習核心,包括 DP 核心,已經透過 oneDNN 庫 (oneAPI 深度神經網路庫) 得到了很好的最佳化,從而降低了核心瓶頸的開銷。
像 GEMM、卷積、反捲積這樣的操作是計算密集型的。而像池化、批次歸一化、ReLU 這樣的啟用函式是記憶體密集型的。
Intel® VTune™ Profiler 的 instrumentation and Tracing Technology (ITT)¶
Intel® VTune Profiler 的 ITT API 是一個有用的工具,可以標記工作負載的某個區域進行追蹤,以便在更細粒度的標記級別(例如 OP/函式/子函式)進行效能分析和視覺化。透過在 PyTorch 模型的操作 (OPs) 級別進行標記,Intel® VTune Profiler 的 ITT 可以實現操作級別的效能分析。Intel® VTune Profiler 的 ITT 已整合到 PyTorch Autograd Profiler 中。1
該功能必須透過 with torch.autograd.profiler.emit_itt() 顯式啟用。
將 TorchServe 與 Intel® Extension for PyTorch* 結合使用¶
Intel® Extension for PyTorch* 是一個 Python 包,用於擴充套件 PyTorch,提供最佳化功能,以在 Intel 硬體上額外提升效能。
Intel® Extension for PyTorch* 已整合到 TorchServe 中,可直接提供效能提升。2 對於自定義處理程式指令碼,我們建議新增 intel_extension_for_pytorch 包。
該功能必須透過在 config.properties 中設定 ipex_enable=true 顯式啟用。
在本節中,我們將展示後端瓶頸通常是未充分最佳化或未充分調優的深度學習工作負載的主要瓶頸,並演示如何透過 Intel® Extension for PyTorch* 改進後端瓶頸的最佳化技術,後端瓶頸有兩個子指標——記憶體瓶頸和核心瓶頸。更高效的記憶體分配器、運算元融合、記憶體佈局格式最佳化可以改進記憶體瓶頸。理想情況下,透過最佳化運算元和更好的快取區域性性,可以將記憶體密集型操作改進為核心密集型操作。而關鍵的深度學習原語,如卷積、矩陣乘法、點積等,已透過 Intel® Extension for PyTorch* 和 oneDNN 庫得到了很好的最佳化,從而改進了核心瓶頸。
利用高階啟動器配置:記憶體分配器¶
從效能角度來看,記憶體分配器起著重要作用。更高效的記憶體使用減少了不必要的記憶體分配或銷燬開銷,從而加快執行速度。在實踐中,對於深度學習工作負載,尤其是在大型多核系統或像 TorchServe 這樣的伺服器上執行的工作負載,TCMalloc 或 JeMalloc 通常比預設的 PyTorch 記憶體分配器 PTMalloc 具有更好的記憶體使用效率。
TCMalloc, JeMalloc, PTMalloc¶
TCMalloc 和 JeMalloc 都使用執行緒本地快取來減少執行緒同步開銷,並分別透過使用自旋鎖和每執行緒競技場來減少鎖競爭。TCMalloc 和 JeMalloc 減少了不必要的記憶體分配和解除分配的開銷。兩種分配器都根據大小對記憶體分配進行分類,以減少記憶體碎片化的開銷。
透過啟動器,使用者可以透過選擇以下三個啟動器旋鈕中的一個輕鬆嘗試不同的記憶體分配器:–enable_tcmalloc (TCMalloc),–enable_jemalloc (JeMalloc),–use_default_allocator (PTMalloc)。
練習¶
讓我們對 PTMalloc 與 JeMalloc 進行效能分析。
我們將使用啟動器指定記憶體分配器,並將工作負載繫結到第一個 socket 的物理核心上,以避免任何 NUMA 複雜性——僅分析記憶體分配器的影響。
以下示例測量 ResNet50 的平均推理時間
import torch
import torchvision.models as models
import time
model = models.resnet50(pretrained=False)
model.eval()
batch_size = 32
data = torch.rand(batch_size, 3, 224, 224)
# warm up
for _ in range(100):
model(data)
# measure
# Intel® VTune Profiler's ITT context manager
with torch.autograd.profiler.emit_itt():
start = time.time()
for i in range(100):
# Intel® VTune Profiler's ITT to annotate each step
torch.profiler.itt.range_push('step_{}'.format(i))
model(data)
torch.profiler.itt.range_pop()
end = time.time()
print('Inference took {:.2f} ms in average'.format((end-start)/100*1000))
讓我們收集 level-1 TMA 指標。

Level-1 TMA 顯示 PTMalloc 和 JeMalloc 都受後端限制。超過一半的執行時間被後端停頓。讓我們深入一層。

Level-2 TMA 顯示後端瓶頸是由記憶體瓶頸引起的。讓我們再深入一層。

記憶體瓶頸下的指標大多用於識別從 L1 快取到主記憶體的記憶體層次結構中哪個級別是瓶頸。在給定級別受限制的熱點表明大部分資料是從該快取或記憶體級別檢索的。最佳化應專注於將資料移近核心。Level-3 TMA 顯示 PTMalloc 受 DRAM 瓶頸限制。另一方面,JeMalloc 受 L1 瓶頸限制——JeMalloc 將資料移近了核心,從而加快了執行速度。
讓我們看看 Intel® VTune Profiler ITT 追蹤。在示例指令碼中,我們標記了推理迴圈的每個 step_x。
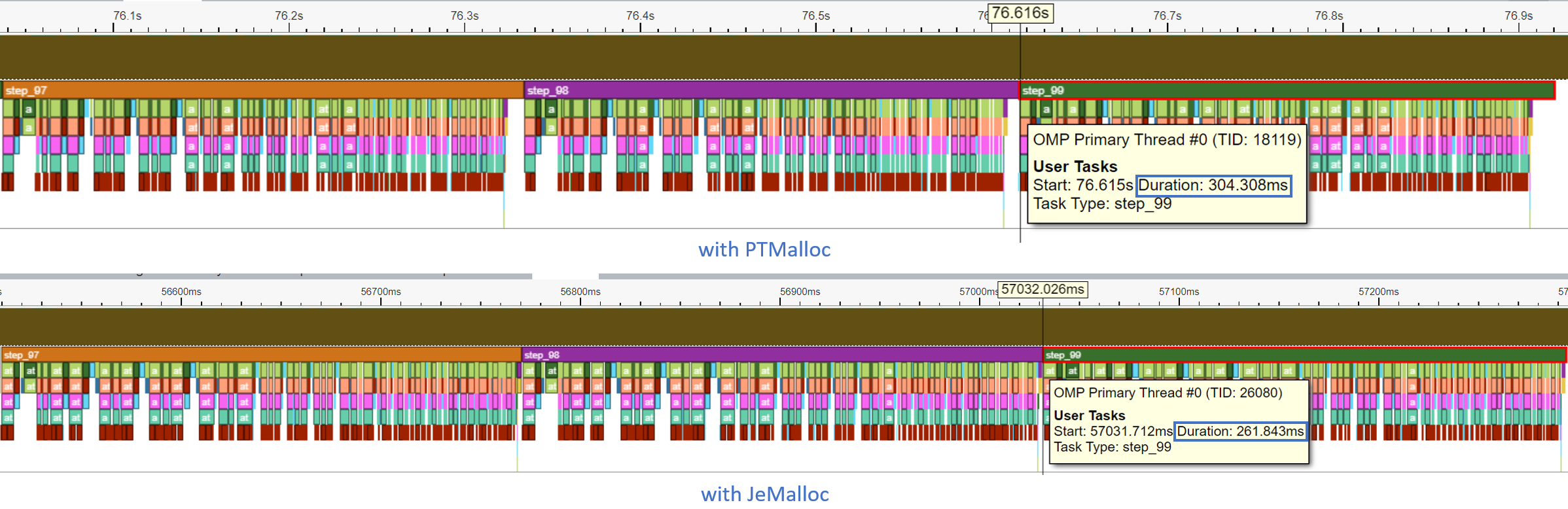
每個步驟都在時間軸圖中進行了追蹤。模型推理在最後一步 (step_99) 的持續時間從 304.308 ms 減少到 261.843 ms。
TorchServe 練習¶
讓我們使用 TorchServe 對 PTMalloc 與 JeMalloc 進行效能分析。
我們將使用 TorchServe apache-bench 基準測試,使用 ResNet50 FP32 模型,批次大小 32,併發度 32,請求數 8960。所有其他引數與預設引數相同。
與前面的練習一樣,我們將使用啟動器指定記憶體分配器,並將工作負載繫結到第一個 socket 的物理核心上。為此,使用者只需在 config.properties 中新增幾行程式碼
PTMalloc
cpu_launcher_enable=true
cpu_launcher_args=--node_id 0 --use_default_allocator
JeMalloc
cpu_launcher_enable=true
cpu_launcher_args=--node_id 0 --enable_jemalloc
讓我們收集 level-1 TMA 指標。

讓我們深入一層。

讓我們使用 Intel® VTune Profiler ITT 標記 TorchServe 推理範圍,以便在推理級別進行細粒度效能分析。由於 TorchServe 架構包含多個子元件,包括用於處理請求/響應的 Java 前端和用於對模型執行實際推理的 Python 後端,因此使用 Intel® VTune Profiler ITT 將追蹤資料的收集限制在推理級別是有幫助的。

每次推理呼叫都在時間軸圖中進行了追蹤。最後一次模型推理的持續時間從 561.688 ms 減少到 251.287 ms - 提速 2.2 倍。
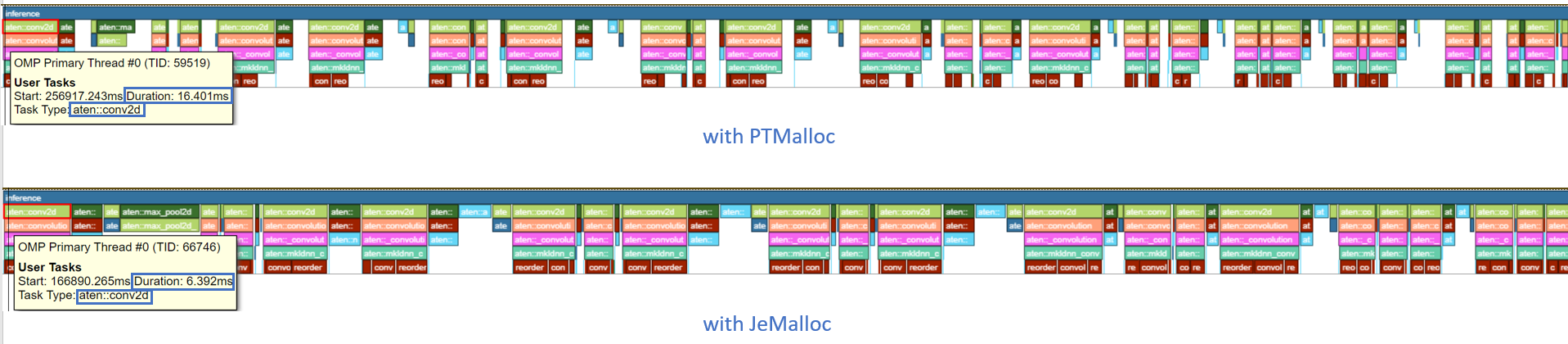
時間軸圖可以展開以檢視操作級別的效能分析結果。aten::conv2d 的持續時間從 16.401 ms 減少到 6.392 ms - 提速 2.6 倍。
在本節中,我們演示了 JeMalloc 比預設的 PyTorch 記憶體分配器 PTMalloc 具有更好的效能,其高效的執行緒本地快取改進了後端瓶頸。
Intel® Extension for PyTorch*¶
Intel® Extension for PyTorch* 的三個主要最佳化技術——運算元、圖、執行時,如下所示
Intel® Extension for PyTorch* 最佳化技術 |
||
|---|---|---|
運算元 |
圖 |
執行時 |
|
|
|
運算元最佳化¶
最佳化的運算元和核心透過 PyTorch 的排程機制註冊。這些運算元和核心透過 Intel 硬體原生的向量化功能和矩陣計算功能得到加速。執行期間,Intel® Extension for PyTorch* 會攔截 ATen 運算元的呼叫,並用這些最佳化的運算元替換原始運算元。諸如 Convolution、Linear 等常用運算元已在 Intel® Extension for PyTorch* 中進行了最佳化。
練習¶
讓我們使用 Intel® Extension for PyTorch* 對最佳化過的運算元進行效能分析。我們將比較程式碼更改前後(即使用和不使用最佳化)的效能。
與前面的練習一樣,我們將工作負載繫結到第一個 socket 的物理核心上。
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv = torch.nn.Conv2d(16, 33, 3, stride=2)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
model = Model()
model.eval()
data = torch.rand(20, 16, 50, 100)
#################### code changes ####################
import intel_extension_for_pytorch as ipex
model = ipex.optimize(model)
######################################################
print(model)
模型包含兩個操作——Conv2d 和 ReLU。透過列印模型物件,我們得到以下輸出。

讓我們收集 level-1 TMA 指標。

注意後端瓶頸從 68.9 減少到 38.5 —— 提速 1.8 倍。
此外,讓我們使用 PyTorch Profiler 進行效能分析。

注意 CPU 時間從 851 us 減少到 310 us —— 提速 2.7 倍。
圖最佳化¶
強烈建議使用者利用 Intel® Extension for PyTorch* 結合 TorchScript 進行進一步的圖最佳化。為了透過 TorchScript 進一步最佳化效能,Intel® Extension for PyTorch* 支援 oneDNN 融合常用的 FP32/BF16 運算元模式,如 Conv2D+ReLU、Linear+ReLU 等,以減少運算元/核心呼叫開銷,並獲得更好的快取區域性性。某些運算元融合允許維護臨時計算、資料型別轉換、資料佈局以獲得更好的快取區域性性。此外,對於 INT8,Intel® Extension for PyTorch* 內建了量化方案,可為包括 CNN、NLP 和推薦模型在內的常見 DL 工作負載提供良好的統計精度。然後,量化後的模型透過 oneDNN 融合支援進行最佳化。
練習¶
讓我們使用 TorchScript 對 FP32 圖最佳化進行效能分析。
與前面的練習一樣,我們將工作負載繫結到第一個 socket 的物理核心上。
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv = torch.nn.Conv2d(16, 33, 3, stride=2)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
model = Model()
model.eval()
data = torch.rand(20, 16, 50, 100)
#################### code changes ####################
import intel_extension_for_pytorch as ipex
model = ipex.optimize(model)
######################################################
# torchscript
with torch.no_grad():
model = torch.jit.trace(model, data)
model = torch.jit.freeze(model)
讓我們收集 level-1 TMA 指標。

注意後端瓶頸從 67.1 減少到 37.5 —— 提速 1.8 倍。
此外,讓我們使用 PyTorch Profiler 進行效能分析。

注意,使用 Intel® Extension for PyTorch* 後,Conv + ReLU 運算元被融合,CPU 時間從 803 us 減少到 248 us —— 提速 3.2 倍。oneDNN 的 eltwise 後處理操作使得可以將一個 primitive 與一個 elementwise primitive 融合。這是最常見的融合型別之一:將 elementwise(通常是 ReLU 等啟用函式)與前面的卷積或內積融合。請參閱下一節中顯示的 oneDNN 詳細日誌。
Channels Last 記憶體格式¶
在模型上呼叫 ipex.optimize 時,Intel® Extension for PyTorch* 會自動將模型轉換為最佳化的記憶體格式,即 channels last。Channels last 是一種對 Intel 架構更友好的記憶體格式。與 PyTorch 預設的 channels first NCHW(批次、通道、高度、寬度)記憶體格式相比,channels last NHWC(批次、高度、寬度、通道)記憶體格式通常透過更好的快取區域性性來加速卷積神經網路。
需要注意的一點是,轉換記憶體格式的開銷很大。因此,最好在部署前轉換一次記憶體格式,並在部署過程中儘量減少記憶體格式轉換。隨著資料透過模型的層傳播,channels last 記憶體格式會透過連續支援 channels last 的層(例如 Conv2d -> ReLU -> Conv2d)得到保留,轉換僅在不支援 channels last 的層之間進行。有關更多詳細資訊,請參閱記憶體格式傳播。
練習¶
讓我們演示 channels last 最佳化。
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv = torch.nn.Conv2d(16, 33, 3, stride=2)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
model = Model()
model.eval()
data = torch.rand(20, 16, 50, 100)
import intel_extension_for_pytorch as ipex
############################### code changes ###############################
ipex.disable_auto_channels_last() # omit this line for channels_last (default)
############################################################################
model = ipex.optimize(model)
with torch.no_grad():
model = torch.jit.trace(model, data)
model = torch.jit.freeze(model)
我們將使用 oneDNN 詳細模式,這是一個有助於在 oneDNN 圖級別收集資訊的工具,例如運算元融合、執行 oneDNN primitives 所花費的核心執行時間。有關更多資訊,請參閱 oneDNN 文件。
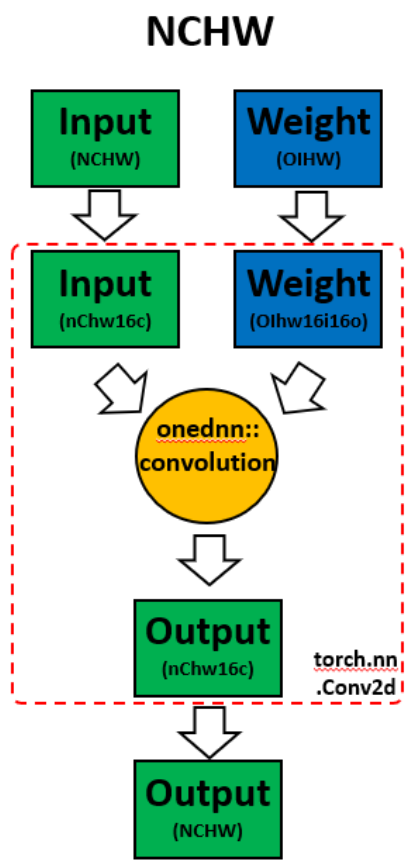
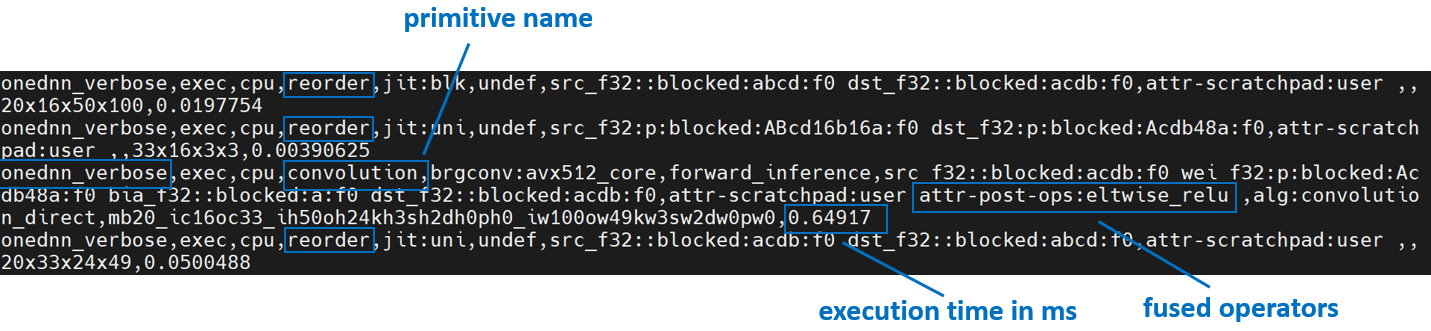
上面是來自 channels first 的 oneDNN 詳細輸出。我們可以驗證,資料和權重會進行重新排序,然後進行計算,最後將輸出重新排序回去。

上面是來自 channels last 的 oneDNN 詳細輸出。我們可以驗證,channels last 記憶體格式避免了不必要的重新排序。
使用 Intel® Extension for PyTorch* 提升效能¶
下面總結了使用 Intel® Extension for PyTorch* 結合 TorchServe 對 ResNet50 和 BERT-base-uncased 的效能提升。
TorchServe 練習¶
讓我們使用 TorchServe 對 Intel® Extension for PyTorch* 最佳化進行效能分析。
我們將使用 TorchServe apache-bench 基準測試,使用 ResNet50 FP32 TorchScript 模型,批次大小 32,併發度 32,請求數 8960。所有其他引數與預設引數相同。
與前面的練習一樣,我們將使用啟動器將工作負載繫結到第一個 socket 的物理核心上。為此,使用者只需在 config.properties 中新增幾行程式碼
cpu_launcher_enable=true
cpu_launcher_args=--node_id 0
讓我們收集 level-1 TMA 指標。

Level-1 TMA 顯示兩者都受後端限制。正如前面討論的,大多數未調優的深度學習工作負載都會受後端瓶頸限制。注意後端瓶頸從 70.0 減少到 54.1。讓我們深入一層。

正如前面討論的,後端瓶頸有兩個子指標——記憶體瓶頸和核心瓶頸。記憶體瓶頸表示工作負載未充分最佳化或未充分利用,理想情況下,透過最佳化運算元並改進快取區域性性,可以將記憶體密集型操作改進為核心密集型操作。Level-2 TMA 顯示後端瓶頸從記憶體瓶頸改進為核心瓶頸。讓我們再深入一層。

在像 TorchServe 這樣的模型服務框架上擴充套件深度學習模型以用於生產環境需要高計算利用率。這要求在執行單元需要資料來執行微操作 (uOps) 時,資料可以透過預取和在快取中重用而可用。Level-3 TMA 顯示後端記憶體瓶頸從 DRAM 瓶頸改進為核心瓶頸。
與前面使用 TorchServe 的練習一樣,讓我們使用 Intel® VTune Profiler ITT 標記 TorchServe 推理範圍,以便在推理級別進行細粒度效能分析。

每次推理呼叫都在時間軸圖中進行了追蹤。最後一次推理呼叫的持續時間從 215.731 ms 減少到 95.634 ms - 提速 2.3 倍。

時間軸圖可以展開以檢視操作級別的效能分析結果。注意 Conv + ReLU 已被融合,持續時間從 6.393 ms + 1.731 ms 減少到 3.408 ms - 提速 2.4 倍。
結論¶
在本教程中,我們使用了自頂向下微架構分析 (TMA) 和 Intel® VTune™ Profiler 的 Instrumentation and Tracing Technology (ITT) 來證明
未充分最佳化或未充分調優的深度學習工作負載的主要瓶頸通常是後端瓶頸,它有兩個子指標:記憶體瓶頸和核心瓶頸。
更高效的記憶體分配器、運算元融合、記憶體佈局格式最佳化(由 Intel® Extension for PyTorch* 提供)可以改進記憶體瓶頸。
關鍵的深度學習原語,如卷積、矩陣乘法、點積等,已透過 Intel® Extension for PyTorch* 和 oneDNN 庫得到了很好的最佳化,從而改進了核心瓶頸。
Intel® Extension for PyTorch* 已整合到 TorchServe 中,並提供了易於使用的 API。
整合 Intel® Extension for PyTorch* 的 TorchServe 在 ResNet50 上顯示出 7.71 倍的吞吐量加速,在 BERT 上顯示出 2.20 倍的吞吐量加速。
致謝¶
我們要感謝 Ashok Emani (Intel) 和 Jiong Gong (Intel) 在本教程的多個步驟中給予的巨大指導、支援、詳盡反饋和評審。我們還要感謝 Hamid Shojanazeri (Meta) 和 Li Ning (AWS) 在程式碼評審和本教程中提供的有益反饋。
