


注意
點選 此處 下載完整示例程式碼
多語言資料的強制對齊¶
作者: Xiaohui Zhang, Moto Hira.
本教程展示瞭如何對非英語語言的文字與語音進行對齊。
對齊非英語(歸一化)文字的過程與對齊英語(歸一化)文字的過程相同,關於英語的詳細過程已在 CTC 強制對齊教程 中進行介紹。在本教程中,我們使用 TorchAudio 的高階 API,torchaudio.pipelines.Wav2Vec2FABundle,它打包了預訓練模型、分詞器和對齊器,以用更少的程式碼執行強制對齊。
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
2.7.0
2.7.0
cuda
from typing import List
import IPython
import matplotlib.pyplot as plt
建立 pipeline¶
首先,我們例項化模型以及預處理/後處理 pipeline。
下圖說明了對齊的過程。

波形被傳遞給聲學模型,聲學模型生成 token 的機率分佈序列。文字被傳遞給分詞器,分詞器將文字轉換為 token 序列。對齊器接收來自聲學模型和分詞器的結果,併為每個 token 生成時間戳。
注意
這個過程要求輸入文字已經過歸一化。歸一化過程涉及非英語語言的羅馬化,這取決於具體的語言,因此本教程不詳細介紹,但我們會簡要地看一下。
聲學模型和分詞器必須使用相同的 token 集合。為了方便建立匹配的處理器,Wav2Vec2FABundle 關聯了預訓練聲學模型和一個分詞器。torchaudio.pipelines.MMS_FA 是這樣一個例項。
以下程式碼例項化了一個預訓練聲學模型、一個使用與模型相同 token 集合的分詞器以及一個對齊器。
注意
MMS_FA 的 get_model() 方法例項化的模型預設包含 <star> token 的特徵維度。您可以透過傳遞 with_star=False 來停用此功能。
MMS_FA 的聲學模型是研究專案“將語音技術擴充套件到 1000 多種語言”的一部分,已被建立並開源。該模型使用了來自 1100 多種語言的 23,000 小時音訊進行訓練。
分詞器簡單地將歸一化的字元對映到整數。您可以按如下方式檢查對映;
print(bundle.get_dict())
{'-': 0, 'a': 1, 'i': 2, 'e': 3, 'n': 4, 'o': 5, 'u': 6, 't': 7, 's': 8, 'r': 9, 'm': 10, 'k': 11, 'l': 12, 'd': 13, 'g': 14, 'h': 15, 'y': 16, 'b': 17, 'p': 18, 'w': 19, 'c': 20, 'v': 21, 'j': 22, 'z': 23, 'f': 24, "'": 25, 'q': 26, 'x': 27, '*': 28}
對齊器內部使用 torchaudio.functional.forced_align() 和 torchaudio.functional.merge_tokens() 來推斷輸入 token 的時間戳。
底層機制的詳細資訊已在 CTC 強制對齊 API 教程 中介紹,請參考該教程。
我們定義了一個實用函式,它使用上述模型、分詞器和對齊器執行強制對齊。
def compute_alignments(waveform: torch.Tensor, transcript: List[str]):
with torch.inference_mode():
emission, _ = model(waveform.to(device))
token_spans = aligner(emission[0], tokenizer(transcript))
return emission, token_spans
我們還定義了用於繪製結果和預覽音訊片段的實用函式。
# Compute average score weighted by the span length
def _score(spans):
return sum(s.score * len(s) for s in spans) / sum(len(s) for s in spans)
def plot_alignments(waveform, token_spans, emission, transcript, sample_rate=bundle.sample_rate):
ratio = waveform.size(1) / emission.size(1) / sample_rate
fig, axes = plt.subplots(2, 1)
axes[0].imshow(emission[0].detach().cpu().T, aspect="auto")
axes[0].set_title("Emission")
axes[0].set_xticks([])
axes[1].specgram(waveform[0], Fs=sample_rate)
for t_spans, chars in zip(token_spans, transcript):
t0, t1 = t_spans[0].start, t_spans[-1].end
axes[0].axvspan(t0 - 0.5, t1 - 0.5, facecolor="None", hatch="/", edgecolor="white")
axes[1].axvspan(ratio * t0, ratio * t1, facecolor="None", hatch="/", edgecolor="white")
axes[1].annotate(f"{_score(t_spans):.2f}", (ratio * t0, sample_rate * 0.51), annotation_clip=False)
for span, char in zip(t_spans, chars):
t0 = span.start * ratio
axes[1].annotate(char, (t0, sample_rate * 0.55), annotation_clip=False)
axes[1].set_xlabel("time [second]")
fig.tight_layout()
def preview_word(waveform, spans, num_frames, transcript, sample_rate=bundle.sample_rate):
ratio = waveform.size(1) / num_frames
x0 = int(ratio * spans[0].start)
x1 = int(ratio * spans[-1].end)
print(f"{transcript} ({_score(spans):.2f}): {x0 / sample_rate:.3f} - {x1 / sample_rate:.3f} sec")
segment = waveform[:, x0:x1]
return IPython.display.Audio(segment.numpy(), rate=sample_rate)
歸一化文字¶
傳遞給 pipeline 的文字必須事先進行歸一化。確切的歸一化過程取決於具體的語言。
沒有顯式詞邊界的語言(如中文、日文和韓文)需要先進行分詞。有專門的工具可以完成此任務,但假設我們已經有了分好詞的文字。
歸一化的第一步是羅馬化。uroman 是一個支援多種語言的工具。
以下是使用 uroman 將輸入文字檔案羅馬化並將輸出寫入另一個文字檔案的 BASH 命令。
$ echo "des événements d'actualité qui se sont produits durant l'année 1882" > text.txt
$ uroman/bin/uroman.pl < text.txt > text_romanized.txt
$ cat text_romanized.txt
Cette page concerne des evenements d'actualite qui se sont produits durant l'annee 1882
下一步是刪除非字母和標點符號。以下程式碼片段對羅馬化後的文字進行歸一化。
import re
def normalize_uroman(text):
text = text.lower()
text = text.replace("’", "'")
text = re.sub("([^a-z' ])", " ", text)
text = re.sub(' +', ' ', text)
return text.strip()
with open("text_romanized.txt", "r") as f:
for line in f:
text_normalized = normalize_uroman(line)
print(text_normalized)
在上面的示例上執行指令碼會產生以下結果。
cette page concerne des evenements d'actualite qui se sont produits durant l'annee
注意,在此示例中,由於 “1882” 沒有被 uroman 羅馬化,因此在歸一化步驟中被刪除了。為了避免這種情況,需要對數字進行羅馬化,但這被認為是一項非平凡的任務。
對齊文字與語音¶
現在我們對多種語言執行強制對齊。
德語¶
text_raw = "aber seit ich bei ihnen das brot hole"
text_normalized = "aber seit ich bei ihnen das brot hole"
url = "https://download.pytorch.org/torchaudio/tutorial-assets/10349_8674_000087.flac"
waveform, sample_rate = torchaudio.load(
url, frame_offset=int(0.5 * bundle.sample_rate), num_frames=int(2.5 * bundle.sample_rate)
)
assert sample_rate == bundle.sample_rate
transcript = text_normalized.split()
tokens = tokenizer(transcript)
emission, token_spans = compute_alignments(waveform, transcript)
num_frames = emission.size(1)
plot_alignments(waveform, token_spans, emission, transcript)
print("Raw Transcript: ", text_raw)
print("Normalized Transcript: ", text_normalized)
IPython.display.Audio(waveform, rate=sample_rate)
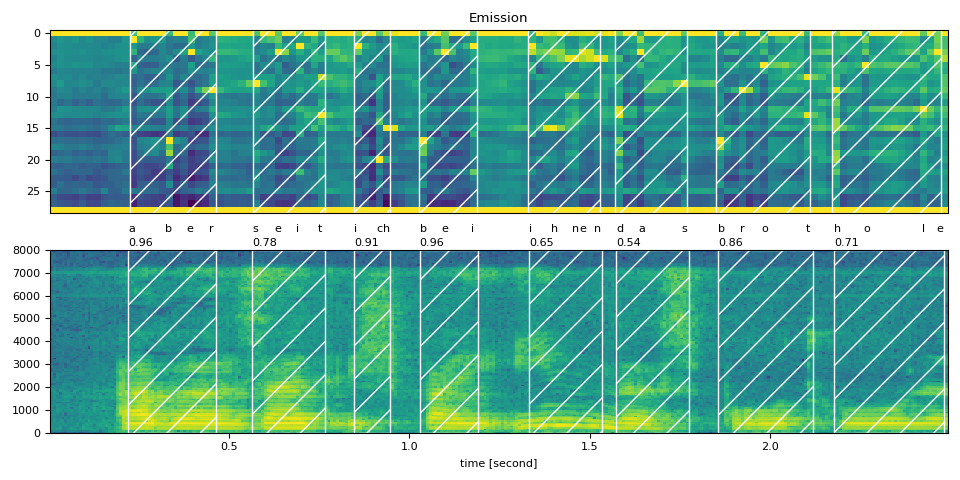
Raw Transcript: aber seit ich bei ihnen das brot hole
Normalized Transcript: aber seit ich bei ihnen das brot hole
preview_word(waveform, token_spans[0], num_frames, transcript[0])
aber (0.96): 0.222 - 0.464 sec
preview_word(waveform, token_spans[1], num_frames, transcript[1])
seit (0.78): 0.565 - 0.766 sec
preview_word(waveform, token_spans[2], num_frames, transcript[2])
ich (0.91): 0.847 - 0.948 sec
preview_word(waveform, token_spans[3], num_frames, transcript[3])
bei (0.96): 1.028 - 1.190 sec
preview_word(waveform, token_spans[4], num_frames, transcript[4])
ihnen (0.65): 1.331 - 1.532 sec
preview_word(waveform, token_spans[5], num_frames, transcript[5])
das (0.54): 1.573 - 1.774 sec
preview_word(waveform, token_spans[6], num_frames, transcript[6])
brot (0.86): 1.855 - 2.117 sec
preview_word(waveform, token_spans[7], num_frames, transcript[7])
hole (0.71): 2.177 - 2.480 sec
中文¶
中文是基於字元的語言,在其原始書寫形式中沒有顯式的詞級別分詞(透過空格分隔)。為了獲得詞級別對齊,您需要首先使用詞分詞器(如“Stanford Tokenizer”)在詞級別對文字進行分詞。但是,如果您只需要字元級別對齊,則不需要這樣做。
text_raw = "關 服務 高階 產品 仍 處於 供不應求 的 局面"
text_normalized = "guan fuwu gaoduan chanpin reng chuyu gongbuyingqiu de jumian"
assert sample_rate == bundle.sample_rate
transcript = text_normalized.split()
emission, token_spans = compute_alignments(waveform, transcript)
num_frames = emission.size(1)
plot_alignments(waveform, token_spans, emission, transcript)
print("Raw Transcript: ", text_raw)
print("Normalized Transcript: ", text_normalized)
IPython.display.Audio(waveform, rate=sample_rate)
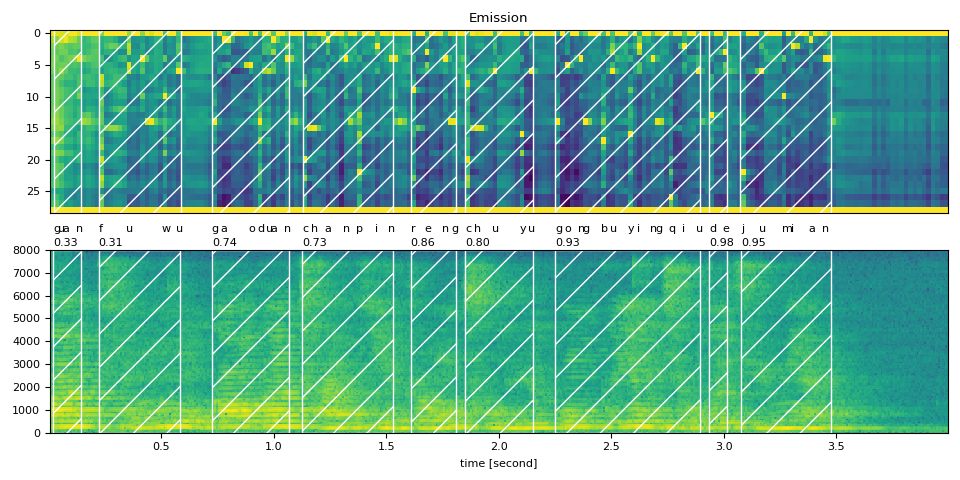
Raw Transcript: 關 服務 高階 產品 仍 處於 供不應求 的 局面
Normalized Transcript: guan fuwu gaoduan chanpin reng chuyu gongbuyingqiu de jumian
preview_word(waveform, token_spans[0], num_frames, transcript[0])
guan (0.33): 0.020 - 0.141 sec
preview_word(waveform, token_spans[1], num_frames, transcript[1])
fuwu (0.31): 0.221 - 0.583 sec
preview_word(waveform, token_spans[2], num_frames, transcript[2])
gaoduan (0.74): 0.724 - 1.065 sec
preview_word(waveform, token_spans[3], num_frames, transcript[3])
chanpin (0.73): 1.126 - 1.528 sec
preview_word(waveform, token_spans[4], num_frames, transcript[4])
reng (0.86): 1.608 - 1.809 sec
preview_word(waveform, token_spans[5], num_frames, transcript[5])
chuyu (0.80): 1.849 - 2.151 sec
preview_word(waveform, token_spans[6], num_frames, transcript[6])
gongbuyingqiu (0.93): 2.251 - 2.894 sec
preview_word(waveform, token_spans[7], num_frames, transcript[7])
de (0.98): 2.935 - 3.015 sec
preview_word(waveform, token_spans[8], num_frames, transcript[8])
jumian (0.95): 3.075 - 3.477 sec
波蘭語¶
text_raw = "wtedy ujrzałem na jego brzuchu okrągłą czarną ranę"
text_normalized = "wtedy ujrzalem na jego brzuchu okragla czarna rane"
url = "https://download.pytorch.org/torchaudio/tutorial-assets/5090_1447_000088.flac"
waveform, sample_rate = torchaudio.load(url, num_frames=int(4.5 * bundle.sample_rate))
assert sample_rate == bundle.sample_rate
transcript = text_normalized.split()
emission, token_spans = compute_alignments(waveform, transcript)
num_frames = emission.size(1)
plot_alignments(waveform, token_spans, emission, transcript)
print("Raw Transcript: ", text_raw)
print("Normalized Transcript: ", text_normalized)
IPython.display.Audio(waveform, rate=sample_rate)
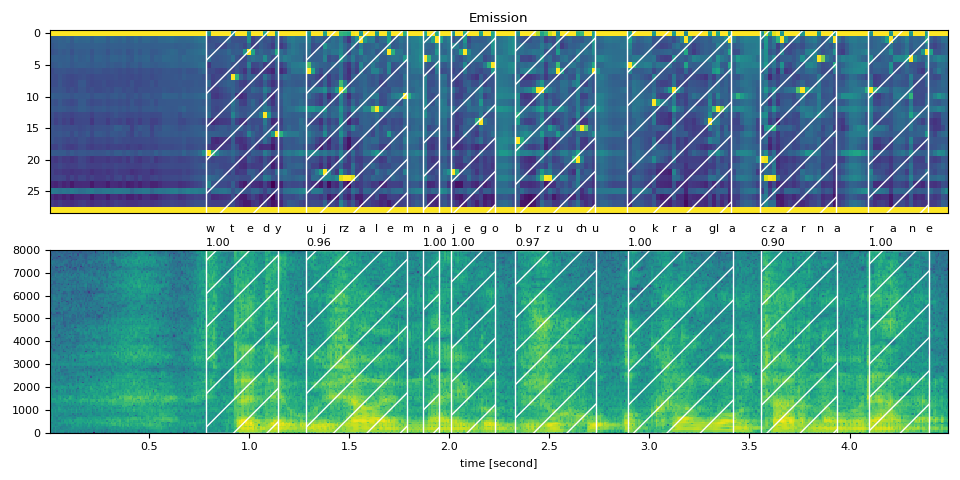
Raw Transcript: wtedy ujrzałem na jego brzuchu okrągłą czarną ranę
Normalized Transcript: wtedy ujrzalem na jego brzuchu okragla czarna rane
preview_word(waveform, token_spans[0], num_frames, transcript[0])
wtedy (1.00): 0.783 - 1.145 sec
preview_word(waveform, token_spans[1], num_frames, transcript[1])
ujrzalem (0.96): 1.286 - 1.788 sec
preview_word(waveform, token_spans[2], num_frames, transcript[2])
na (1.00): 1.868 - 1.949 sec
preview_word(waveform, token_spans[3], num_frames, transcript[3])
jego (1.00): 2.009 - 2.230 sec
preview_word(waveform, token_spans[4], num_frames, transcript[4])
brzuchu (0.97): 2.330 - 2.732 sec
preview_word(waveform, token_spans[5], num_frames, transcript[5])
okragla (1.00): 2.893 - 3.415 sec
preview_word(waveform, token_spans[6], num_frames, transcript[6])
czarna (0.90): 3.556 - 3.938 sec
preview_word(waveform, token_spans[7], num_frames, transcript[7])
rane (1.00): 4.098 - 4.399 sec
葡萄牙語¶
text_raw = "na imensa extensão onde se esconde o inconsciente imortal"
text_normalized = "na imensa extensao onde se esconde o inconsciente imortal"
url = "https://download.pytorch.org/torchaudio/tutorial-assets/6566_5323_000027.flac"
waveform, sample_rate = torchaudio.load(
url, frame_offset=int(bundle.sample_rate), num_frames=int(4.6 * bundle.sample_rate)
)
assert sample_rate == bundle.sample_rate
transcript = text_normalized.split()
emission, token_spans = compute_alignments(waveform, transcript)
num_frames = emission.size(1)
plot_alignments(waveform, token_spans, emission, transcript)
print("Raw Transcript: ", text_raw)
print("Normalized Transcript: ", text_normalized)
IPython.display.Audio(waveform, rate=sample_rate)
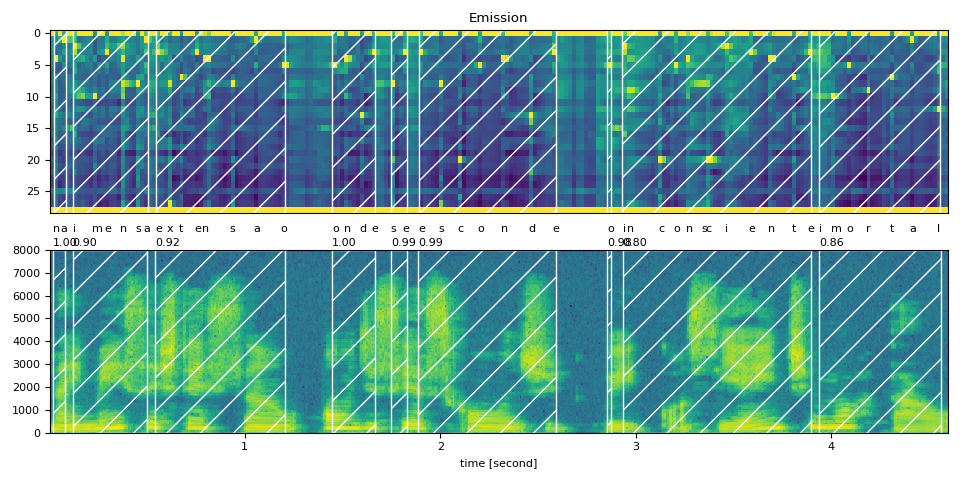
Raw Transcript: na imensa extensão onde se esconde o inconsciente imortal
Normalized Transcript: na imensa extensao onde se esconde o inconsciente imortal
preview_word(waveform, token_spans[0], num_frames, transcript[0])
na (1.00): 0.020 - 0.080 sec
preview_word(waveform, token_spans[1], num_frames, transcript[1])
imensa (0.90): 0.120 - 0.502 sec
preview_word(waveform, token_spans[2], num_frames, transcript[2])
extensao (0.92): 0.542 - 1.205 sec
preview_word(waveform, token_spans[3], num_frames, transcript[3])
onde (1.00): 1.446 - 1.667 sec
preview_word(waveform, token_spans[4], num_frames, transcript[4])
se (0.99): 1.748 - 1.828 sec
preview_word(waveform, token_spans[5], num_frames, transcript[5])
esconde (0.99): 1.888 - 2.591 sec
preview_word(waveform, token_spans[6], num_frames, transcript[6])
o (0.98): 2.852 - 2.872 sec
preview_word(waveform, token_spans[7], num_frames, transcript[7])
inconsciente (0.80): 2.933 - 3.897 sec
preview_word(waveform, token_spans[8], num_frames, transcript[8])
imortal (0.86): 3.937 - 4.560 sec
義大利語¶
text_raw = "elle giacean per terra tutte quante"
text_normalized = "elle giacean per terra tutte quante"
url = "https://download.pytorch.org/torchaudio/tutorial-assets/642_529_000025.flac"
waveform, sample_rate = torchaudio.load(url, num_frames=int(4 * bundle.sample_rate))
assert sample_rate == bundle.sample_rate
transcript = text_normalized.split()
emission, token_spans = compute_alignments(waveform, transcript)
num_frames = emission.size(1)
plot_alignments(waveform, token_spans, emission, transcript)
print("Raw Transcript: ", text_raw)
print("Normalized Transcript: ", text_normalized)
IPython.display.Audio(waveform, rate=sample_rate)
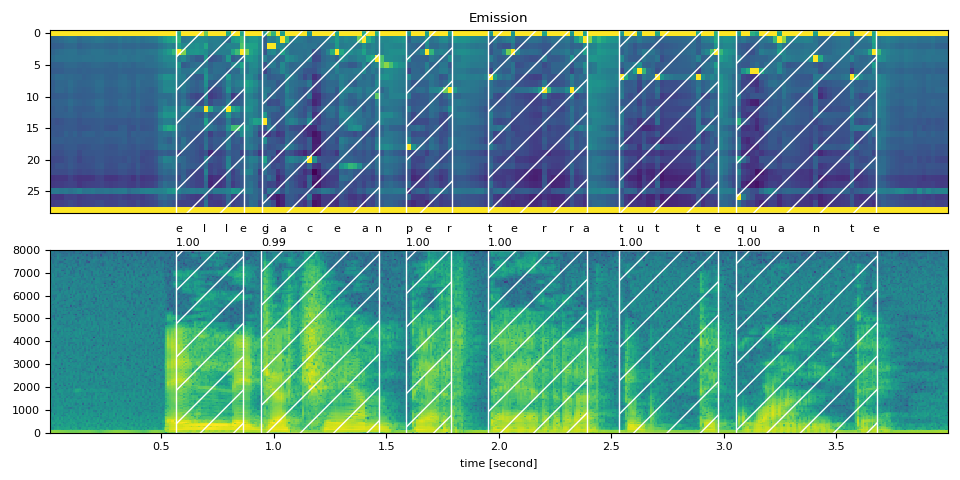
Raw Transcript: elle giacean per terra tutte quante
Normalized Transcript: elle giacean per terra tutte quante
preview_word(waveform, token_spans[0], num_frames, transcript[0])
elle (1.00): 0.563 - 0.864 sec
preview_word(waveform, token_spans[1], num_frames, transcript[1])
giacean (0.99): 0.945 - 1.467 sec
preview_word(waveform, token_spans[2], num_frames, transcript[2])
per (1.00): 1.588 - 1.789 sec
preview_word(waveform, token_spans[3], num_frames, transcript[3])
terra (1.00): 1.950 - 2.392 sec
preview_word(waveform, token_spans[4], num_frames, transcript[4])
tutte (1.00): 2.533 - 2.975 sec
preview_word(waveform, token_spans[5], num_frames, transcript[5])
quante (1.00): 3.055 - 3.678 sec
結論¶
在本教程中,我們介紹瞭如何使用 torchaudio 的強制對齊 API 和一個 Wav2Vec2 預訓練的多語言聲學模型,將五種語言的語音資料與文字進行對齊。
致謝¶
感謝 Vineel Pratap 和 Zhaoheng Ni 開發並開源了強制對齊器 API。
指令碼總執行時間: ( 0 分 4.835 秒)
