


注意
點選 這裡 下載完整示例程式碼
StreamReader 高階用法¶
作者: Moto Hira
本教程是 StreamReader 基本用法 的續篇。
本教程展示瞭如何將 StreamReader 用於
裝置輸入,例如麥克風、網路攝像頭和螢幕錄製
生成合成音訊/影片
使用自定義過濾器表示式應用預處理
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
import IPython
import matplotlib.pyplot as plt
from torchaudio.io import StreamReader
base_url = "https://download.pytorch.org/torchaudio/tutorial-assets"
AUDIO_URL = f"{base_url}/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav"
VIDEO_URL = f"{base_url}/stream-api/NASAs_Most_Scientifically_Complex_Space_Observatory_Requires_Precision-MP4.mp4"
2.7.0
2.7.0
音訊/影片裝置輸入¶
假設系統擁有適當的媒體裝置,並且 libavdevice 配置為使用這些裝置,則流式 API 可以從這些裝置中拉取媒體流。
為此,我們將附加引數 format 和 option 傳遞給建構函式。format 指定裝置元件,option 字典特定於指定的元件。
需要傳遞的具體引數取決於系統配置。詳情請參閱 https://ffmpeg.org/ffmpeg-devices.html。
以下示例說明了如何在 MacBook Pro 上執行此操作。
首先,我們需要檢查可用的裝置。
$ ffmpeg -f avfoundation -list_devices true -i ""
[AVFoundation indev @ 0x143f04e50] AVFoundation video devices:
[AVFoundation indev @ 0x143f04e50] [0] FaceTime HD Camera
[AVFoundation indev @ 0x143f04e50] [1] Capture screen 0
[AVFoundation indev @ 0x143f04e50] AVFoundation audio devices:
[AVFoundation indev @ 0x143f04e50] [0] MacBook Pro Microphone
我們使用 FaceTime HD Camera 作為影片裝置(索引 0),使用 MacBook Pro Microphone 作為音訊裝置(索引 0)。
如果我們不傳遞任何 option,裝置將使用其預設配置。解碼器可能不支援該配置。
>>> StreamReader(
... src="0:0", # The first 0 means `FaceTime HD Camera`, and
... # the second 0 indicates `MacBook Pro Microphone`.
... format="avfoundation",
... )
[avfoundation @ 0x125d4fe00] Selected framerate (29.970030) is not supported by the device.
[avfoundation @ 0x125d4fe00] Supported modes:
[avfoundation @ 0x125d4fe00] 1280x720@[1.000000 30.000000]fps
[avfoundation @ 0x125d4fe00] 640x480@[1.000000 30.000000]fps
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
...
RuntimeError: Failed to open the input: 0:0
透過提供 option,我們可以將裝置流的格式更改為解碼器支援的格式。
>>> streamer = StreamReader(
... src="0:0",
... format="avfoundation",
... option={"framerate": "30", "pixel_format": "bgr0"},
... )
>>> for i in range(streamer.num_src_streams):
... print(streamer.get_src_stream_info(i))
SourceVideoStream(media_type='video', codec='rawvideo', codec_long_name='raw video', format='bgr0', bit_rate=0, width=640, height=480, frame_rate=30.0)
SourceAudioStream(media_type='audio', codec='pcm_f32le', codec_long_name='PCM 32-bit floating point little-endian', format='flt', bit_rate=3072000, sample_rate=48000.0, num_channels=2)
合成源流¶
作為裝置整合的一部分,ffmpeg 提供了一個“虛擬裝置”介面。該介面使用 libavfilter 生成合成音訊/影片資料。
要使用此功能,我們將 format 設定為 lavfi,並向 src 提供過濾器描述。
過濾器描述的詳細資訊可以在 https://ffmpeg.org/ffmpeg-filters.html 中找到
音訊示例¶
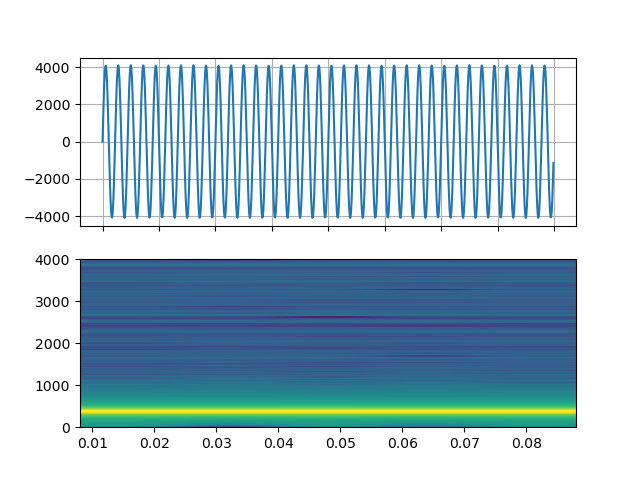
正弦波¶
https://ffmpeg.org/ffmpeg-filters.html#sine
StreamReader(src="sine=sample_rate=8000:frequency=360", format="lavfi")
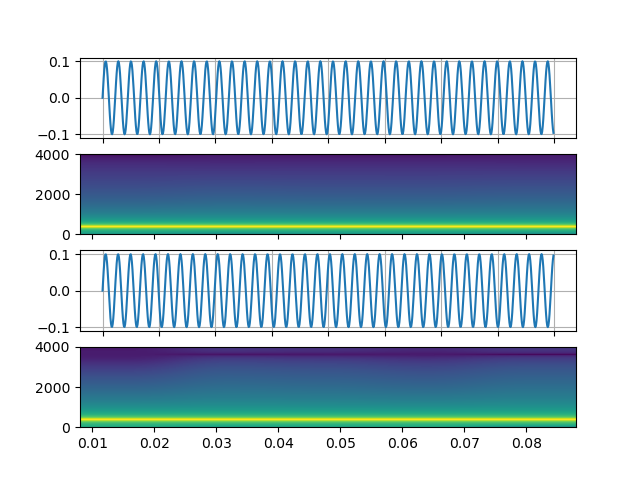
任意表達式訊號¶
https://ffmpeg.org/ffmpeg-filters.html#aevalsrc
# 5 Hz binaural beats on a 360 Hz carrier
StreamReader(
src=(
'aevalsrc='
'sample_rate=8000:'
'exprs=0.1*sin(2*PI*(360-5/2)*t)|0.1*sin(2*PI*(360+5/2)*t)'
),
format='lavfi',
)
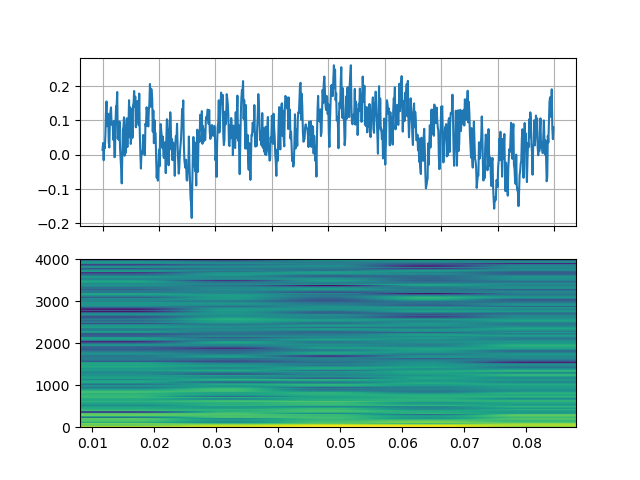
噪聲¶
https://ffmpeg.org/ffmpeg-filters.html#anoisesrc
StreamReader(src="anoisesrc=color=pink:sample_rate=8000:amplitude=0.5", format="lavfi")
影片示例¶
細胞自動機¶
https://ffmpeg.org/ffmpeg-filters.html#cellauto
StreamReader(src=f"cellauto", format="lavfi")
Mandelbrot¶
https://ffmpeg.org/ffmpeg-filters.html#cellauto
StreamReader(src=f"mandelbrot", format="lavfi")
MPlayer 測試模式¶
https://ffmpeg.org/ffmpeg-filters.html#mptestsrc
StreamReader(src=f"mptestsrc", format="lavfi")
John Conway 的生命遊戲¶
https://ffmpeg.org/ffmpeg-filters.html#life
StreamReader(src=f"life", format="lavfi")
Sierpinski 地毯/三角形分形¶
https://ffmpeg.org/ffmpeg-filters.html#sierpinski
StreamReader(src=f"sierpinski", format="lavfi")
自定義過濾器¶
定義輸出流時,可以使用 add_audio_stream() 和 add_video_stream() 方法。
這些方法接受 filter_desc 引數,該引數是按照 ffmpeg 的 過濾器表示式 格式化的字串。
add_basic_(audio|video)_stream 和 add_(audio|video)_stream 之間的區別在於 add_basic_(audio|video)_stream 構建過濾器表示式並將其傳遞給相同的底層實現。add_basic_(audio|video)_stream 可以實現的所有功能都可以透過 add_(audio|video)_stream 實現。
注意
應用自定義過濾器時,客戶端程式碼必須將音訊/影片流轉換為 torchaudio 可以轉換為 tensor 格式的格式之一。例如,可以透過對影片流應用
format=pix_fmts=rgb24和對音訊流應用aformat=sample_fmts=fltp來實現這一點。每個輸出流都有單獨的過濾器圖。因此,無法對一個過濾器表示式使用不同的輸入/輸出流。但是,可以將一個輸入流分割成多個流,並在之後合併它們。
音訊示例¶
# fmt: off
descs = [
# No filtering
"anull",
# Apply a highpass filter then a lowpass filter
"highpass=f=200,lowpass=f=1000",
# Manipulate spectrogram
(
"afftfilt="
"real='hypot(re,im)*sin(0)':"
"imag='hypot(re,im)*cos(0)':"
"win_size=512:"
"overlap=0.75"
),
# Manipulate spectrogram
(
"afftfilt="
"real='hypot(re,im)*cos((random(0)*2-1)*2*3.14)':"
"imag='hypot(re,im)*sin((random(1)*2-1)*2*3.14)':"
"win_size=128:"
"overlap=0.8"
),
]
# fmt: on
sample_rate = 8000
streamer = StreamReader(AUDIO_URL)
for desc in descs:
streamer.add_audio_stream(
frames_per_chunk=40000,
filter_desc=f"aresample={sample_rate},{desc},aformat=sample_fmts=fltp",
)
chunks = next(streamer.stream())
def _display(i):
print("filter_desc:", streamer.get_out_stream_info(i).filter_description)
fig, axs = plt.subplots(2, 1)
waveform = chunks[i][:, 0]
axs[0].plot(waveform)
axs[0].grid(True)
axs[0].set_ylim([-1, 1])
plt.setp(axs[0].get_xticklabels(), visible=False)
axs[1].specgram(waveform, Fs=sample_rate)
fig.tight_layout()
return IPython.display.Audio(chunks[i].T, rate=sample_rate)
原始¶
_display(0)
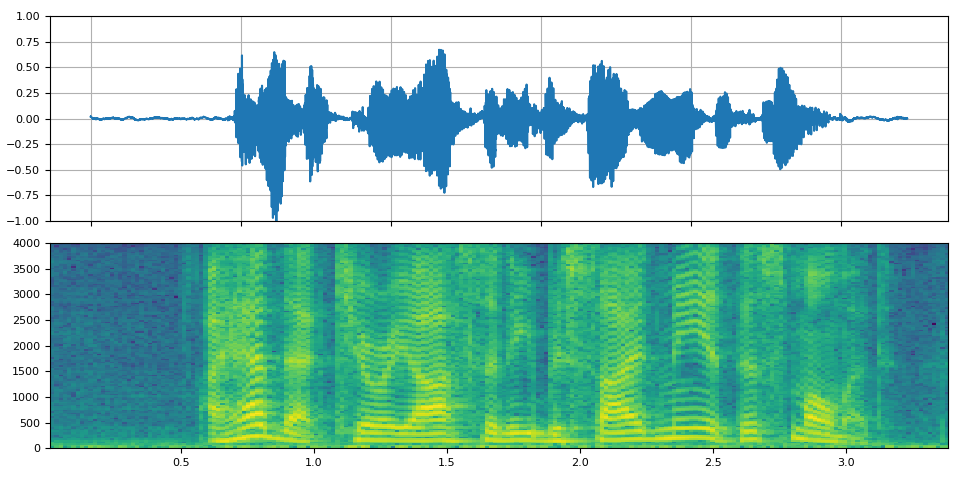
filter_desc: aresample=8000,anull,aformat=sample_fmts=fltp
高通/低通濾波器¶
_display(1)
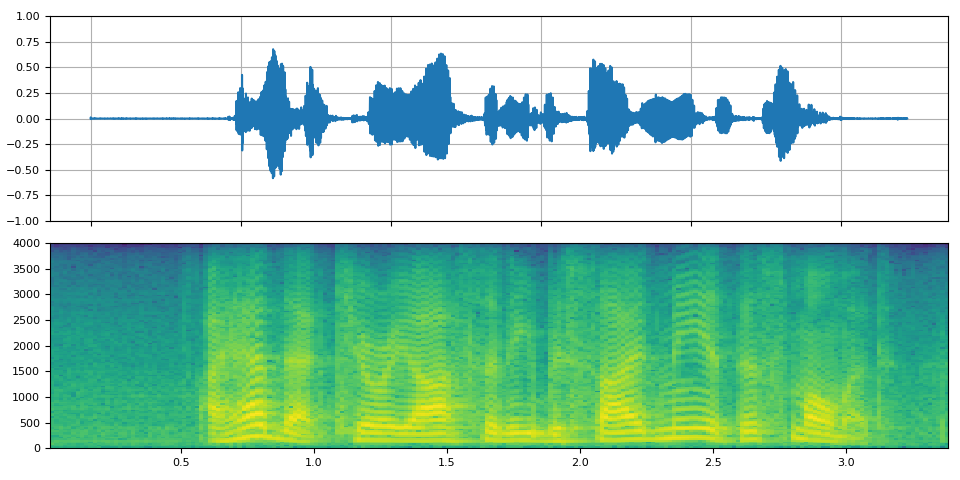
filter_desc: aresample=8000,highpass=f=200,lowpass=f=1000,aformat=sample_fmts=fltp
FFT 濾波器 - 機器人 🤖¶
_display(2)
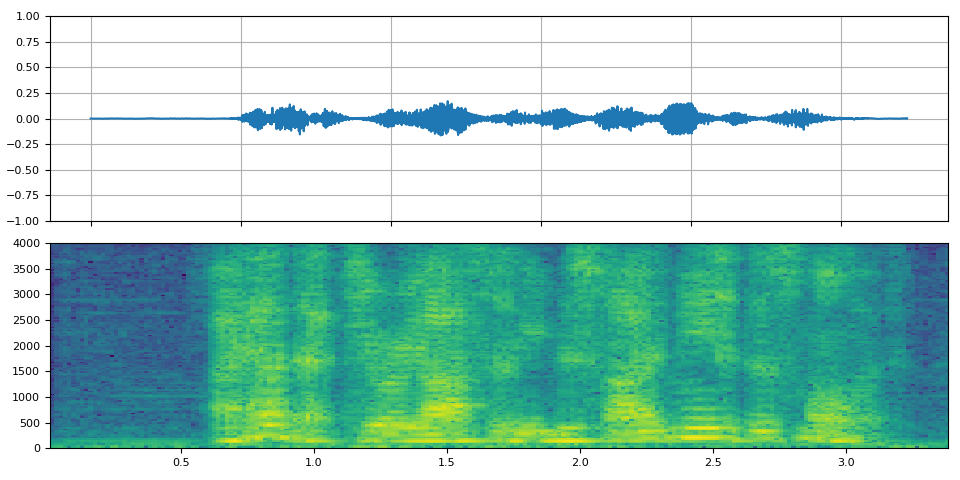
filter_desc: aresample=8000,afftfilt=real='hypot(re,im)*sin(0)':imag='hypot(re,im)*cos(0)':win_size=512:overlap=0.75,aformat=sample_fmts=fltp
FFT 濾波器 - 低語¶
_display(3)
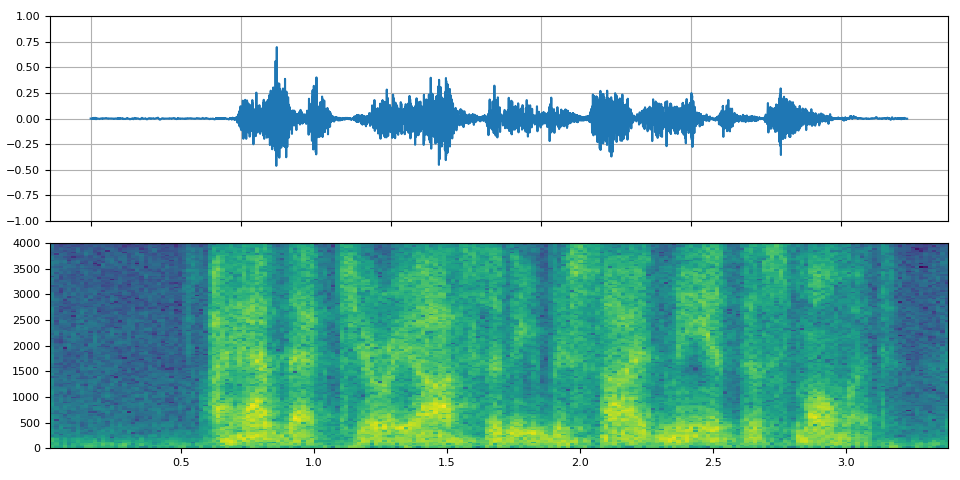
filter_desc: aresample=8000,afftfilt=real='hypot(re,im)*cos((random(0)*2-1)*2*3.14)':imag='hypot(re,im)*sin((random(1)*2-1)*2*3.14)':win_size=128:overlap=0.8,aformat=sample_fmts=fltp
影片示例¶
# fmt: off
descs = [
# No effect
"null",
# Split the input stream and apply horizontal flip to the right half.
(
"split [main][tmp];"
"[tmp] crop=iw/2:ih:0:0, hflip [flip];"
"[main][flip] overlay=W/2:0"
),
# Edge detection
"edgedetect=mode=canny",
# Rotate image by randomly and fill the background with brown
"rotate=angle=-random(1)*PI:fillcolor=brown",
# Manipulate pixel values based on the coordinate
"geq=r='X/W*r(X,Y)':g='(1-X/W)*g(X,Y)':b='(H-Y)/H*b(X,Y)'"
]
# fmt: on
streamer = StreamReader(VIDEO_URL)
for desc in descs:
streamer.add_video_stream(
frames_per_chunk=30,
filter_desc=f"fps=10,{desc},format=pix_fmts=rgb24",
)
streamer.seek(12)
chunks = next(streamer.stream())
def _display(i):
print("filter_desc:", streamer.get_out_stream_info(i).filter_description)
_, axs = plt.subplots(1, 3, figsize=(8, 1.9))
chunk = chunks[i]
for j in range(3):
axs[j].imshow(chunk[10 * j + 1].permute(1, 2, 0))
axs[j].set_axis_off()
plt.tight_layout()
原始¶
_display(0)

filter_desc: fps=10,null,format=pix_fmts=rgb24
映象¶
_display(1)

filter_desc: fps=10,split [main][tmp];[tmp] crop=iw/2:ih:0:0, hflip [flip];[main][flip] overlay=W/2:0,format=pix_fmts=rgb24
邊緣檢測¶
_display(2)

filter_desc: fps=10,edgedetect=mode=canny,format=pix_fmts=rgb24
隨機旋轉¶
_display(3)

filter_desc: fps=10,rotate=angle=-random(1)*PI:fillcolor=brown,format=pix_fmts=rgb24
畫素操作¶
_display(4)

filter_desc: fps=10,geq=r='X/W*r(X,Y)':g='(1-X/W)*g(X,Y)':b='(H-Y)/H*b(X,Y)',format=pix_fmts=rgb24
標籤: torchaudio.io
指令碼總執行時間: ( 0 分 18.695 秒)
