


注意
點選此處下載完整示例程式碼
StreamWriter 基本用法¶
作者: Moto Hira
本教程展示如何使用 torchaudio.io.StreamWriter 將音訊/影片資料編碼並儲存為各種格式/目的地。
注意
本教程需要 FFmpeg 庫。詳細資訊請參閱FFmpeg 依賴項。
警告
TorchAudio 會動態載入系統上安裝的相容 FFmpeg 庫。支援的格式型別(媒體格式、編碼器、編碼器選項等)取決於這些庫。
要檢查可用的複用器和編碼器,可以使用以下命令
ffmpeg -muxers
ffmpeg -encoders
準備工作¶
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
from torchaudio.io import StreamWriter
print("FFmpeg library versions")
for k, v in torchaudio.utils.ffmpeg_utils.get_versions().items():
print(f" {k}: {v}")
2.7.0
2.7.0
FFmpeg library versions
libavcodec: (60, 3, 100)
libavdevice: (60, 1, 100)
libavfilter: (9, 3, 100)
libavformat: (60, 3, 100)
libavutil: (58, 2, 100)
import io
import os
import tempfile
from IPython.display import Audio, Video
from torchaudio.utils import download_asset
SAMPLE_PATH = download_asset("tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav")
WAVEFORM, SAMPLE_RATE = torchaudio.load(SAMPLE_PATH, channels_first=False)
NUM_FRAMES, NUM_CHANNELS = WAVEFORM.shape
_BASE_DIR = tempfile.TemporaryDirectory()
def get_path(filename):
return os.path.join(_BASE_DIR.name, filename)
基本用法¶
要使用 StreamWriter 將 Tensor 資料儲存為媒體格式,需要完成以下三個必要步驟
指定輸出
配置流
寫入資料
以下程式碼示例說明如何將音訊資料儲存為 WAV 檔案。
# 2. Configure the stream. (8kHz, Stereo WAV)
s.add_audio_stream(
sample_rate=SAMPLE_RATE,
num_channels=NUM_CHANNELS,
)
# 3. Write the data
with s.open():
s.write_audio_chunk(0, WAVEFORM)
Audio(path)
現在我們更詳細地檢視每個步驟。
寫入目的地¶
StreamWriter 支援不同型別的寫入目的地
本地檔案
類檔案物件
流媒體協議(如 RTMP 和 UDP)
媒體裝置(揚聲器和影片播放器)†
† 對於媒體裝置,請參閱StreamWriter 高階用法。
本地檔案¶
StreamWriter 支援將媒體儲存到本地檔案。
StreamWriter(dst="audio.wav")
StreamWriter(dst="audio.mp3")
這也適用於靜態影像和影片。
StreamWriter(dst="image.jpeg")
StreamWriter(dst="video.mpeg")
類檔案物件¶
您也可以傳遞一個類檔案物件。類檔案物件必須實現符合 io.RawIOBase.write 的 write 方法。
# Open the local file as fileobj
with open("audio.wav", "wb") as dst:
StreamWriter(dst=dst)
# In-memory encoding
buffer = io.BytesIO()
StreamWriter(dst=buffer)
流媒體協議¶
您可以使用流媒體協議流式傳輸媒體
# Real-Time Messaging Protocol
StreamWriter(dst="rtmp://:1234/live/app", format="flv")
# UDP
StreamWriter(dst="udp://:48550", format="mpegts")
配置輸出流¶
指定目的地後,下一步是配置流。對於典型的音訊和靜態影像情況,只需要一個流,但對於帶音訊的影片,至少需要配置兩個流(一個用於音訊,另一個用於影片)。
音訊流¶
可以使用 add_audio_stream() 方法新增音訊流。
對於寫入常規音訊檔案,至少需要 sample_rate 和 num_channels。
s = StreamWriter("audio.wav")
s.add_audio_stream(sample_rate=8000, num_channels=2)
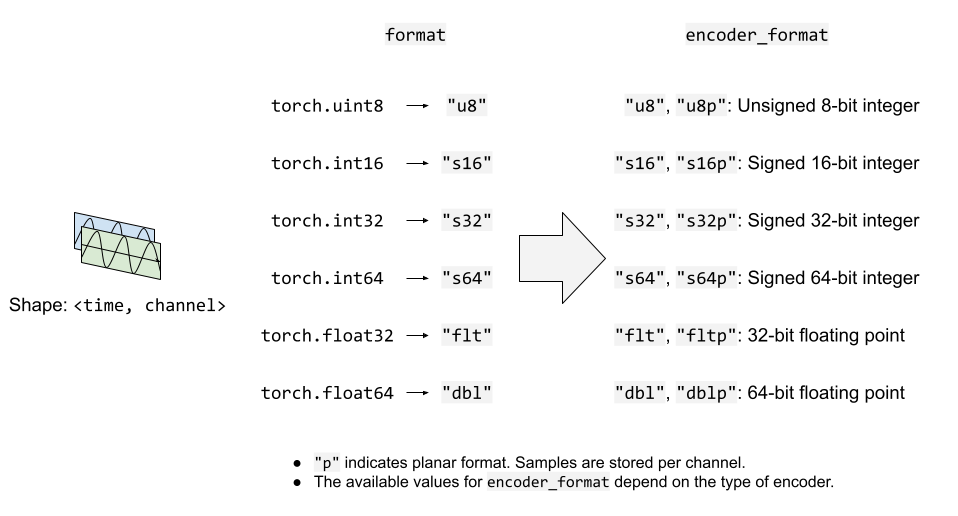
預設情況下,音訊流期望輸入的波形張量型別為 torch.float32。在上述情況下,資料將編碼為 WAV 格式的預設編碼格式,即 16 位有符號整數線性 PCM。StreamWriter 在內部轉換取樣格式。
如果編碼器支援多種取樣格式並且您想更改編碼器取樣格式,可以使用 encoder_format 選項。
在以下示例中,StreamWriter 期望輸入波形張量的資料型別為 torch.float32,但在編碼時會將其轉換為 16 位有符號整數。
s = StreamWriter("audio.mp3")
s.add_audio_stream(
...,
encoder="libmp3lame", # "libmp3lame" is often the default encoder for mp3,
# but specifying it manually, for the sake of illustration.
encoder_format="s16p", # "libmp3lame" encoder supports the following sample format.
# - "s16p" (16-bit signed integer)
# - "s32p" (32-bit signed integer)
# - "fltp" (32-bit floating point)
)
如果您的波形張量的資料型別不是 torch.float32,您可以提供 format 選項來更改期望的資料型別。
以下示例配置 StreamWriter 期望 torch.int16 型別的 Tensor。
# Audio data passed to StreamWriter must be torch.int16
s.add_audio_stream(..., format="s16")
下圖說明了 format 和 encoder_format 選項如何作用於音訊流。
影片流¶
要新增靜態影像或影片流,可以使用 add_video_stream() 方法。
至少需要 frame_rate、height 和 width。
s = StreamWriter("video.mp4")
s.add_video_stream(frame_rate=10, height=96, width=128)
對於靜態影像,請使用 frame_rate=1。
s = StreamWriter("image.png")
s.add_video_stream(frame_rate=1, ...)
與音訊流類似,您可以提供 format 和 encoder_format 選項來控制輸入資料和編碼的格式。
以下示例將影片資料編碼為 YUV422 格式。
s = StreamWriter("video.mov")
s.add_video_stream(
...,
encoder="libx264", # libx264 supports different YUV formats, such as
# yuv420p yuvj420p yuv422p yuvj422p yuv444p yuvj444p nv12 nv16 nv21
encoder_format="yuv422p", # StreamWriter will convert the input data to YUV422 internally
)
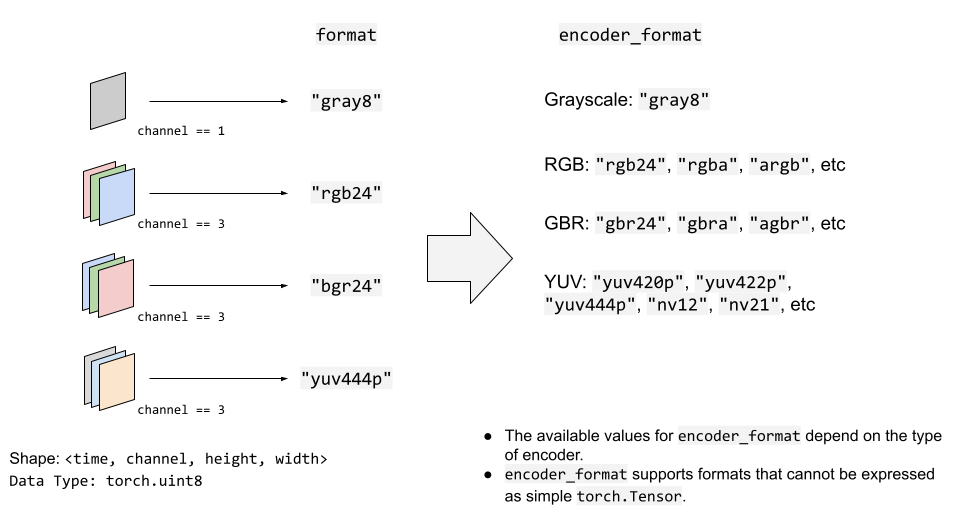
YUV 格式常用於影片編碼。許多 YUV 格式的色度通道平面大小與亮度通道不同。這使得很難直接將其表示為 torch.Tensor 型別。因此,StreamWriter 將自動將輸入的影片 Tensor 轉換為目標格式。
StreamWriter 期望輸入影像張量為 4 維(時間、通道、高度、寬度)且型別為 torch.uint8。
預設顏色通道是 RGB,即對應紅、綠、藍的三種顏色通道。如果您的輸入使用不同的顏色通道,例如 BGR 和 YUV,您可以使用 format 選項指定。
以下示例指定 BGR 格式。
s.add_video_stream(..., format="bgr24")
# Image data passed to StreamWriter must have
# three color channels representing Blue Green Red.
#
# The shape of the input tensor has to be
# (time, channel==3, height, width)
下圖說明了 format 和 encoder_format 選項如何作用於影片流。
寫入資料¶
配置好流後,下一步是開啟輸出位置並開始寫入資料。
使用 open() 方法開啟目的地,然後使用 write_audio_chunk() 和/或 write_video_chunk() 寫入資料。
音訊張量應具有 (時間, 通道) 的形狀,影片/影像張量應具有 (時間, 通道, 高度, 寬度) 的形狀。
通道數、高度和寬度必須與相應流的配置匹配,該配置由 "format" 選項指定。
表示靜態影像的張量在時間維度上必須只有一幀,但音訊和影片張量在時間維度上可以有任意數量的幀。
以下程式碼片段對此進行了說明;
例) 音訊¶
# Configure stream
s = StreamWriter(dst=get_path("audio.wav"))
s.add_audio_stream(sample_rate=SAMPLE_RATE, num_channels=NUM_CHANNELS)
# Write data
with s.open():
s.write_audio_chunk(0, WAVEFORM)
例) 影像¶
# Image config
height = 96
width = 128
# Configure stream
s = StreamWriter(dst=get_path("image.png"))
s.add_video_stream(frame_rate=1, height=height, width=width, format="rgb24")
# Generate image
chunk = torch.randint(256, (1, 3, height, width), dtype=torch.uint8)
# Write data
with s.open():
s.write_video_chunk(0, chunk)
例) 無音訊影片¶
# Video config
frame_rate = 30
height = 96
width = 128
# Configure stream
s = StreamWriter(dst=get_path("video.mp4"))
s.add_video_stream(frame_rate=frame_rate, height=height, width=width, format="rgb24")
# Generate video chunk (3 seconds)
time = int(frame_rate * 3)
chunk = torch.randint(256, (time, 3, height, width), dtype=torch.uint8)
# Write data
with s.open():
s.write_video_chunk(0, chunk)
例) 帶音訊影片¶
要寫入帶音訊的影片,必須配置單獨的流。
# Configure stream
s = StreamWriter(dst=get_path("video.mp4"))
s.add_audio_stream(sample_rate=SAMPLE_RATE, num_channels=NUM_CHANNELS)
s.add_video_stream(frame_rate=frame_rate, height=height, width=width, format="rgb24")
# Generate audio/video chunk (3 seconds)
time = int(SAMPLE_RATE * 3)
audio_chunk = torch.randn((time, NUM_CHANNELS))
time = int(frame_rate * 3)
video_chunk = torch.randint(256, (time, 3, height, width), dtype=torch.uint8)
# Write data
with s.open():
s.write_audio_chunk(0, audio_chunk)
s.write_video_chunk(1, video_chunk)
逐塊寫入資料¶
寫入資料時,可以將資料沿時間維度分割,並按較小的塊寫入。
# Write data in one-go
dst1 = io.BytesIO()
s = StreamWriter(dst=dst1, format="mp3")
s.add_audio_stream(SAMPLE_RATE, NUM_CHANNELS)
with s.open():
s.write_audio_chunk(0, WAVEFORM)
# Write data in smaller chunks
dst2 = io.BytesIO()
s = StreamWriter(dst=dst2, format="mp3")
s.add_audio_stream(SAMPLE_RATE, NUM_CHANNELS)
with s.open():
for start in range(0, NUM_FRAMES, SAMPLE_RATE):
end = start + SAMPLE_RATE
s.write_audio_chunk(0, WAVEFORM[start:end, ...])
# Check that the contents are same
dst1.seek(0)
bytes1 = dst1.read()
print(f"bytes1: {len(bytes1)}")
print(f"{bytes1[:10]}...{bytes1[-10:]}\n")
dst2.seek(0)
bytes2 = dst2.read()
print(f"bytes2: {len(bytes2)}")
print(f"{bytes2[:10]}...{bytes2[-10:]}\n")
assert bytes1 == bytes2
import matplotlib.pyplot as plt
bytes1: 10700
b'ID3\x04\x00\x00\x00\x00\x00"'...b'\xaa\xaa\xaa\xaa\xaa\xaa\xaa\xaa\xaa\xaa'
bytes2: 10700
b'ID3\x04\x00\x00\x00\x00\x00"'...b'\xaa\xaa\xaa\xaa\xaa\xaa\xaa\xaa\xaa\xaa'
示例 - 頻譜視覺化器¶
在本節中,我們使用 StreamWriter 建立音訊的頻譜視覺化並將其儲存為影片檔案。
為了建立頻譜視覺化,我們使用 torchaudio.transforms.Spectrogram 獲取音訊的頻譜表示,使用 matplotlib 生成其視覺化的柵格影像,然後使用 StreamWriter 將其與原始音訊一起轉換為影片。
import torchaudio.transforms as T
準備資料¶
首先,我們準備頻譜圖資料。我們使用 Spectrogram。
我們調整 hop_length,使得頻譜圖的一幀對應於影片的一幀。
frame_rate = 20
n_fft = 4000
trans = T.Spectrogram(
n_fft=n_fft,
hop_length=SAMPLE_RATE // frame_rate, # One FFT per one video frame
normalized=True,
power=1,
)
specs = trans(WAVEFORM.T)[0].T
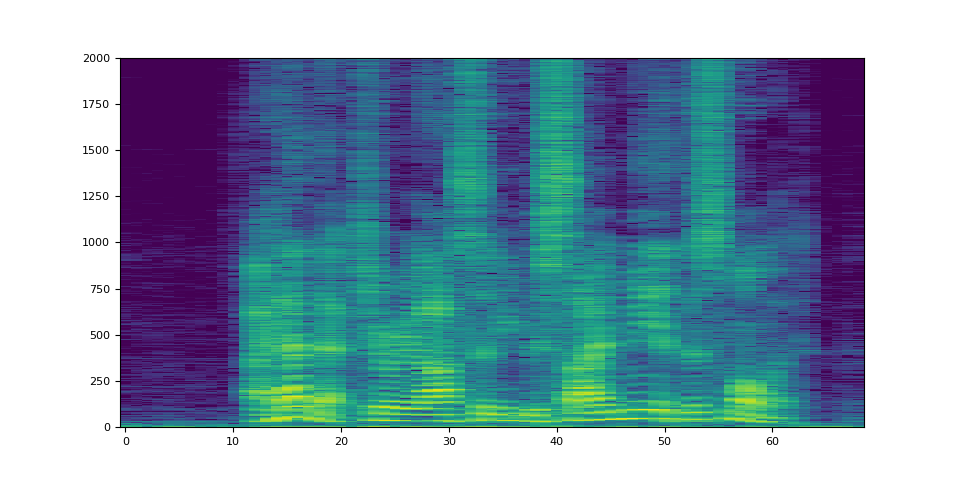
生成的頻譜圖如下所示。
spec_db = T.AmplitudeToDB(stype="magnitude", top_db=80)(specs.T)
_ = plt.imshow(spec_db, aspect="auto", origin="lower")
準備畫布¶
我們使用 matplotlib 逐幀視覺化頻譜圖。我們建立一個輔助函式,用於繪製頻譜圖資料並生成圖形的柵格影像。
fig, ax = plt.subplots(figsize=[3.2, 2.4])
ax.set_position([0, 0, 1, 1])
ax.set_facecolor("black")
ncols, nrows = fig.canvas.get_width_height()
def _plot(data):
ax.clear()
x = list(range(len(data)))
R, G, B = 238 / 255, 76 / 255, 44 / 255
for coeff, alpha in [(0.8, 0.7), (1, 1)]:
d = data**coeff
ax.fill_between(x, d, -d, color=[R, G, B, alpha])
xlim = n_fft // 2 + 1
ax.set_xlim([-1, n_fft // 2 + 1])
ax.set_ylim([-1, 1])
ax.text(
xlim,
0.95,
f"Created with TorchAudio\n{torchaudio.__version__}",
color="white",
ha="right",
va="top",
backgroundcolor="black",
)
fig.canvas.draw()
frame = torch.frombuffer(fig.canvas.tostring_rgb(), dtype=torch.uint8)
return frame.reshape(nrows, ncols, 3).permute(2, 0, 1)
# sphinx_gallery_defer_figures
寫入影片¶
最後,我們使用 StreamWriter 寫入影片。我們一次處理一秒的音訊和影片幀。
s = StreamWriter(get_path("example.mp4"))
s.add_audio_stream(sample_rate=SAMPLE_RATE, num_channels=NUM_CHANNELS)
s.add_video_stream(frame_rate=frame_rate, height=nrows, width=ncols)
with s.open():
i = 0
# Process by second
for t in range(0, NUM_FRAMES, SAMPLE_RATE):
# Write audio chunk
s.write_audio_chunk(0, WAVEFORM[t : t + SAMPLE_RATE, :])
# write 1 second of video chunk
frames = [_plot(spec) for spec in specs[i : i + frame_rate]]
if frames:
s.write_video_chunk(1, torch.stack(frames))
i += frame_rate
plt.close(fig)
/pytorch/audio/examples/tutorials/streamwriter_basic_tutorial.py:566: MatplotlibDeprecationWarning: The tostring_rgb function was deprecated in Matplotlib 3.8 and will be removed two minor releases later. Use buffer_rgba instead.
frame = torch.frombuffer(fig.canvas.tostring_rgb(), dtype=torch.uint8)
/pytorch/audio/examples/tutorials/streamwriter_basic_tutorial.py:566: UserWarning: The given buffer is not writable, and PyTorch does not support non-writable tensors. This means you can write to the underlying (supposedly non-writable) buffer using the tensor. You may want to copy the buffer to protect its data or make it writable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /opt/conda/conda-bld/pytorch_1727971112454/work/torch/csrc/utils/tensor_new.cpp:1560.)
frame = torch.frombuffer(fig.canvas.tostring_rgb(), dtype=torch.uint8)
結果¶
結果如下圖所示。
Video(get_path("example.mp4"), embed=True)
仔細觀看影片,可以觀察到 “s” 的聲音(curiosity、besides、this)在較高頻率側(影片右側)分配了更多能量。
標籤: torchaudio.io
指令碼總執行時間: ( 0 分 7.371 秒)
