


注意
點選此處下載完整示例程式碼
使用 Tacotron2 進行文字轉語音¶
概述¶
本教程展示瞭如何使用 torchaudio 中預訓練的 Tacotron2 構建文字轉語音管道。
文字轉語音管道的流程如下:
文字預處理
首先,輸入文字被編碼成一個符號列表。在本教程中,我們將使用英文字元和音素作為符號。
聲譜圖生成
從編碼後的文字生成聲譜圖。我們使用
Tacotron2模型來完成此步驟。時域轉換
最後一步是將聲譜圖轉換成波形。從聲譜圖生成語音的過程也稱為聲碼器(Vocoder)。在本教程中,使用了三種不同的聲碼器:
WaveRNN、GriffinLim和 Nvidia 的 WaveGlow。
下圖展示了整個流程。
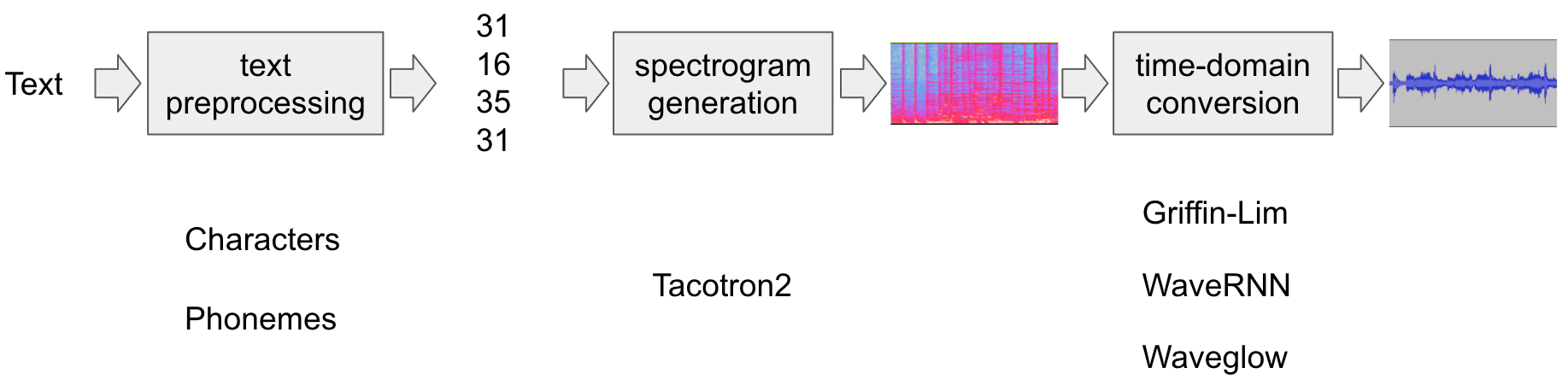
所有相關的元件都捆綁在 torchaudio.pipelines.Tacotron2TTSBundle 中,但本教程也將介紹其底層過程。
準備工作¶
首先,我們安裝必要的依賴項。除了 torchaudio 外,還需要 DeepPhonemizer 來執行基於音素的編碼。
%%bash
pip3 install deep_phonemizer
import torch
import torchaudio
torch.random.manual_seed(0)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(torch.__version__)
print(torchaudio.__version__)
print(device)
2.7.0
2.7.0
cuda
import IPython
import matplotlib.pyplot as plt
文字處理¶
基於字元的編碼¶
在本節中,我們將介紹基於字元的編碼是如何工作的。
由於預訓練的 Tacotron2 模型需要特定的符號表集合,torchaudio 中提供了相同的功能。然而,我們將首先手動實現編碼,以幫助理解。
首先,我們定義符號集合 '_-!\'(),.:;? abcdefghijklmnopqrstuvwxyz'。然後,我們將輸入文字的每個字元對映到表中相應符號的索引。表中不存在的符號將被忽略。
[19, 16, 23, 23, 26, 11, 34, 26, 29, 23, 15, 2, 11, 31, 16, 35, 31, 11, 31, 26, 11, 30, 27, 16, 16, 14, 19, 2]
如上所述,符號表和索引必須與預訓練的 Tacotron2 模型所期望的相匹配。torchaudio 與預訓練模型一起提供了相同的轉換。您可以按如下方式例項化並使用此轉換。
tensor([[19, 16, 23, 23, 26, 11, 34, 26, 29, 23, 15, 2, 11, 31, 16, 35, 31, 11,
31, 26, 11, 30, 27, 16, 16, 14, 19, 2]])
tensor([28], dtype=torch.int32)
注意:我們手動編碼的輸出與 torchaudio text_processor 的輸出匹配(這意味著我們正確地重新實現了庫內部的功能)。它接受一個文字或一個文字列表作為輸入。當提供一個文字列表時,返回的 lengths 變量表示輸出批次中每個已處理 token 的有效長度。
中間表示可以按如下方式獲取:
['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!', ' ', 't', 'e', 'x', 't', ' ', 't', 'o', ' ', 's', 'p', 'e', 'e', 'c', 'h', '!']
基於音素的編碼¶
基於音素的編碼類似於基於字元的編碼,但它使用基於音素的符號表和 G2P(字形到音素)模型。
G2P 模型的細節超出了本教程的範圍,我們將只看看轉換後的樣子。
與基於字元編碼的情況類似,編碼過程應與預訓練的 Tacotron2 模型所訓練的相匹配。torchaudio 提供了一個用於建立此過程的介面。
以下程式碼演示瞭如何建立和使用此過程。在底層,使用 DeepPhonemizer 包建立了一個 G2P 模型,並獲取了 DeepPhonemizer 作者釋出的預訓練權重。
0%| | 0.00/63.6M [00:00<?, ?B/s]
0%| | 128k/63.6M [00:00<01:32, 722kB/s]
1%| | 384k/63.6M [00:00<00:57, 1.15MB/s]
2%|2 | 1.50M/63.6M [00:00<00:18, 3.59MB/s]
8%|7 | 4.88M/63.6M [00:00<00:05, 12.0MB/s]
14%|#3 | 8.62M/63.6M [00:00<00:03, 16.3MB/s]
20%|#9 | 12.6M/63.6M [00:00<00:02, 22.6MB/s]
27%|##7 | 17.2M/63.6M [00:01<00:01, 24.7MB/s]
33%|###3 | 21.1M/63.6M [00:01<00:01, 28.1MB/s]
41%|#### | 26.0M/63.6M [00:01<00:01, 29.0MB/s]
47%|####6 | 29.9M/63.6M [00:01<00:01, 31.2MB/s]
54%|#####4 | 34.6M/63.6M [00:01<00:00, 30.5MB/s]
60%|#####9 | 38.1M/63.6M [00:01<00:00, 31.7MB/s]
68%|######7 | 43.0M/63.6M [00:01<00:00, 36.5MB/s]
73%|#######3 | 46.8M/63.6M [00:02<00:00, 31.2MB/s]
79%|#######8 | 50.2M/63.6M [00:02<00:00, 32.5MB/s]
85%|########5 | 54.4M/63.6M [00:02<00:00, 30.1MB/s]
92%|#########1| 58.2M/63.6M [00:02<00:00, 32.3MB/s]
97%|#########7| 61.9M/63.6M [00:02<00:00, 27.7MB/s]
100%|##########| 63.6M/63.6M [00:02<00:00, 25.0MB/s]
/pytorch/audio/ci_env/lib/python3.10/site-packages/dp/model/model.py:306: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
checkpoint = torch.load(checkpoint_path, map_location=device)
/pytorch/audio/ci_env/lib/python3.10/site-packages/torch/nn/modules/transformer.py:379: UserWarning: enable_nested_tensor is True, but self.use_nested_tensor is False because encoder_layer.self_attn.batch_first was not True(use batch_first for better inference performance)
warnings.warn(
tensor([[54, 20, 65, 69, 11, 92, 44, 65, 38, 2, 11, 81, 40, 64, 79, 81, 11, 81,
20, 11, 79, 77, 59, 37, 2]])
tensor([25], dtype=torch.int32)
注意,編碼後的值與基於字元編碼的示例不同。
中間表示如下所示。
['HH', 'AH', 'L', 'OW', ' ', 'W', 'ER', 'L', 'D', '!', ' ', 'T', 'EH', 'K', 'S', 'T', ' ', 'T', 'AH', ' ', 'S', 'P', 'IY', 'CH', '!']
聲譜圖生成¶
Tacotron2 是我們用來從編碼文字生成聲譜圖的模型。有關模型的詳細資訊,請參閱論文。
使用預訓練權重例項化 Tacotron2 模型非常簡單,但請注意,Tacotron2 模型的輸入需要由匹配的文字處理器進行處理。
torchaudio.pipelines.Tacotron2TTSBundle 將匹配的模型和處理器捆綁在一起,以便輕鬆建立管道。
有關可用捆綁包及其用法,請參閱 Tacotron2TTSBundle。
bundle = torchaudio.pipelines.TACOTRON2_WAVERNN_PHONE_LJSPEECH
processor = bundle.get_text_processor()
tacotron2 = bundle.get_tacotron2().to(device)
text = "Hello world! Text to speech!"
with torch.inference_mode():
processed, lengths = processor(text)
processed = processed.to(device)
lengths = lengths.to(device)
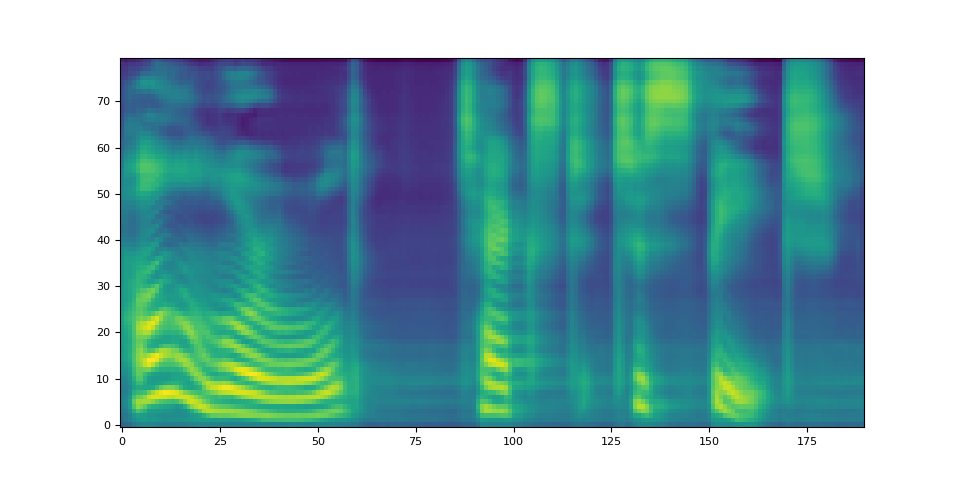
spec, _, _ = tacotron2.infer(processed, lengths)
_ = plt.imshow(spec[0].cpu().detach(), origin="lower", aspect="auto")
/pytorch/audio/ci_env/lib/python3.10/site-packages/dp/model/model.py:306: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
checkpoint = torch.load(checkpoint_path, map_location=device)
/pytorch/audio/ci_env/lib/python3.10/site-packages/torch/nn/modules/transformer.py:379: UserWarning: enable_nested_tensor is True, but self.use_nested_tensor is False because encoder_layer.self_attn.batch_first was not True(use batch_first for better inference performance)
warnings.warn(
Downloading: "https://download.pytorch.org/torchaudio/models/tacotron2_english_phonemes_1500_epochs_wavernn_ljspeech.pth" to /root/.cache/torch/hub/checkpoints/tacotron2_english_phonemes_1500_epochs_wavernn_ljspeech.pth
0%| | 0.00/107M [00:00<?, ?B/s]
14%|#3 | 14.8M/107M [00:00<00:00, 155MB/s]
27%|##7 | 29.5M/107M [00:00<00:01, 54.3MB/s]
35%|###5 | 37.8M/107M [00:00<00:01, 51.5MB/s]
44%|####3 | 46.9M/107M [00:00<00:01, 55.6MB/s]
50%|####9 | 53.4M/107M [00:01<00:01, 51.0MB/s]
60%|#####9 | 64.0M/107M [00:01<00:00, 47.1MB/s]
73%|#######3 | 78.9M/107M [00:01<00:00, 51.7MB/s]
78%|#######8 | 84.1M/107M [00:01<00:00, 46.9MB/s]
89%|########9 | 96.0M/107M [00:01<00:00, 48.8MB/s]
100%|#########9| 107M/107M [00:02<00:00, 44.7MB/s]
100%|##########| 107M/107M [00:02<00:00, 49.9MB/s]
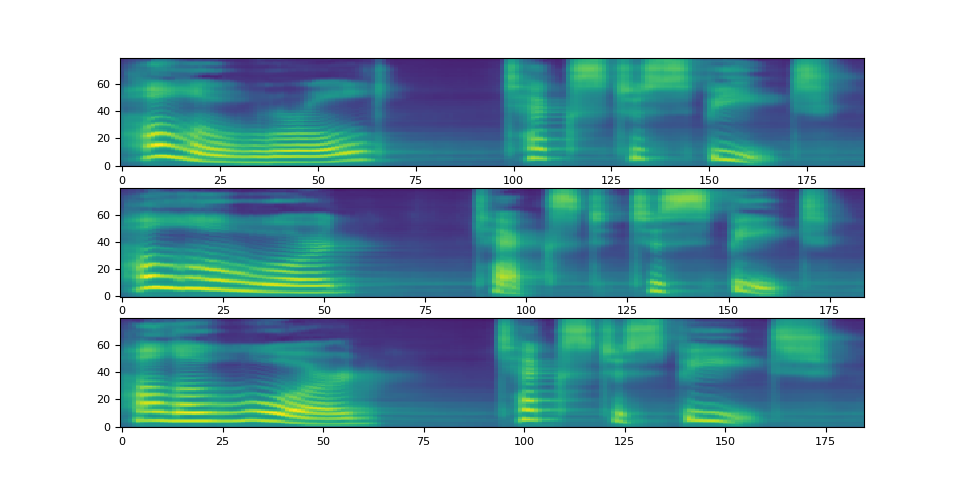
注意,Tacotron2.infer 方法執行多項式取樣,因此聲譜圖生成過程會引入隨機性。
def plot():
fig, ax = plt.subplots(3, 1)
for i in range(3):
with torch.inference_mode():
spec, spec_lengths, _ = tacotron2.infer(processed, lengths)
print(spec[0].shape)
ax[i].imshow(spec[0].cpu().detach(), origin="lower", aspect="auto")
plot()
torch.Size([80, 190])
torch.Size([80, 184])
torch.Size([80, 185])
波形生成¶
聲譜圖生成後,最後一步是使用聲碼器從聲譜圖中恢復波形。
torchaudio 提供了基於 GriffinLim 和 WaveRNN 的聲碼器。
WaveRNN 聲碼器¶
繼續上一節的內容,我們可以從同一個捆綁包中例項化匹配的 WaveRNN 模型。
bundle = torchaudio.pipelines.TACOTRON2_WAVERNN_PHONE_LJSPEECH
processor = bundle.get_text_processor()
tacotron2 = bundle.get_tacotron2().to(device)
vocoder = bundle.get_vocoder().to(device)
text = "Hello world! Text to speech!"
with torch.inference_mode():
processed, lengths = processor(text)
processed = processed.to(device)
lengths = lengths.to(device)
spec, spec_lengths, _ = tacotron2.infer(processed, lengths)
waveforms, lengths = vocoder(spec, spec_lengths)
/pytorch/audio/ci_env/lib/python3.10/site-packages/dp/model/model.py:306: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
checkpoint = torch.load(checkpoint_path, map_location=device)
/pytorch/audio/ci_env/lib/python3.10/site-packages/torch/nn/modules/transformer.py:379: UserWarning: enable_nested_tensor is True, but self.use_nested_tensor is False because encoder_layer.self_attn.batch_first was not True(use batch_first for better inference performance)
warnings.warn(
Downloading: "https://download.pytorch.org/torchaudio/models/wavernn_10k_epochs_8bits_ljspeech.pth" to /root/.cache/torch/hub/checkpoints/wavernn_10k_epochs_8bits_ljspeech.pth
0%| | 0.00/16.7M [00:00<?, ?B/s]
89%|########9 | 14.9M/16.7M [00:00<00:00, 65.0MB/s]
100%|##########| 16.7M/16.7M [00:00<00:00, 46.2MB/s]
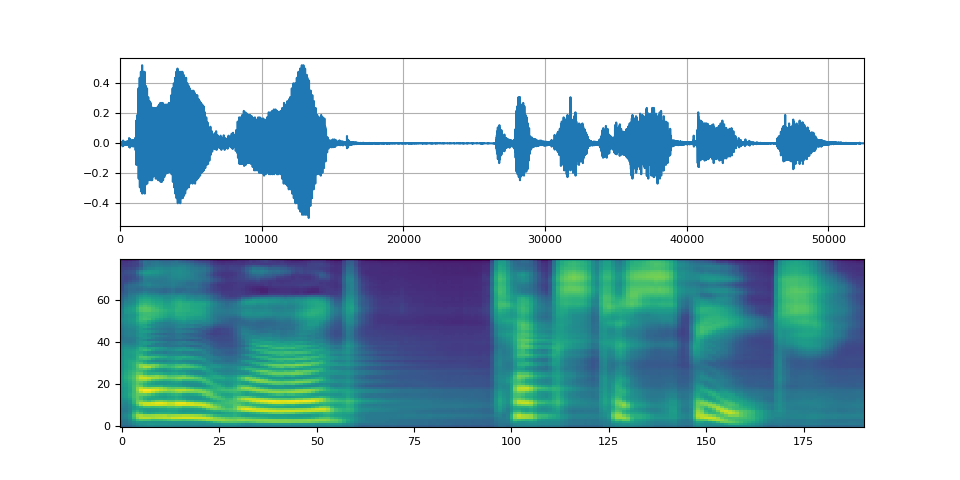
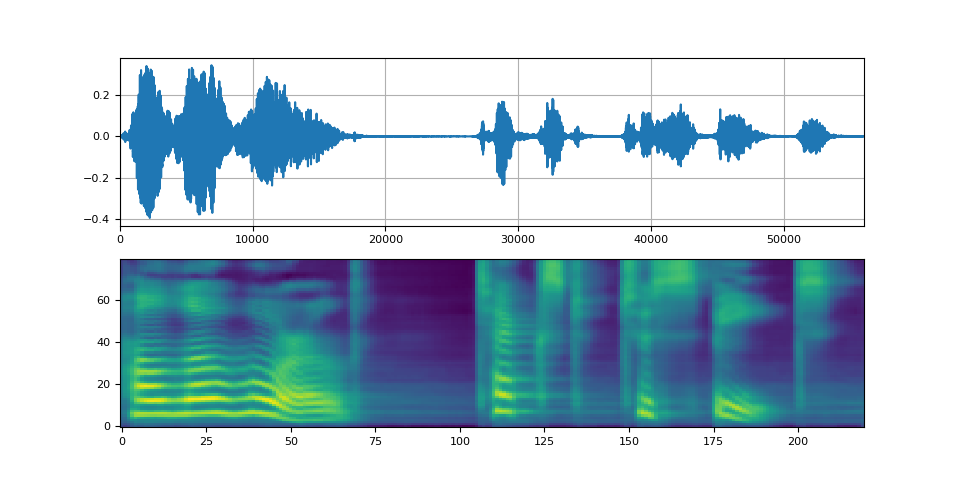
def plot(waveforms, spec, sample_rate):
waveforms = waveforms.cpu().detach()
fig, [ax1, ax2] = plt.subplots(2, 1)
ax1.plot(waveforms[0])
ax1.set_xlim(0, waveforms.size(-1))
ax1.grid(True)
ax2.imshow(spec[0].cpu().detach(), origin="lower", aspect="auto")
return IPython.display.Audio(waveforms[0:1], rate=sample_rate)
plot(waveforms, spec, vocoder.sample_rate)
Griffin-Lim 聲碼器¶
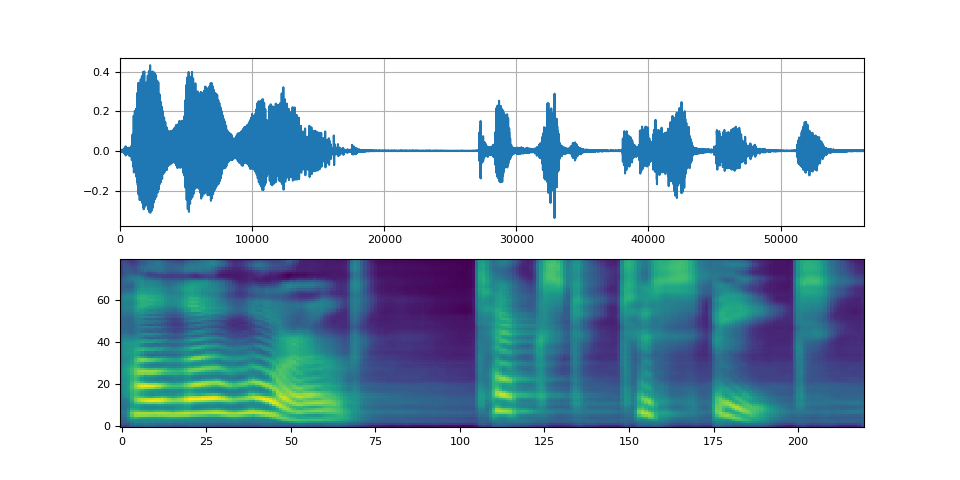
使用 Griffin-Lim 聲碼器與使用 WaveRNN 相同。您可以使用 get_vocoder() 方法例項化聲碼器物件,並傳入聲譜圖。
bundle = torchaudio.pipelines.TACOTRON2_GRIFFINLIM_PHONE_LJSPEECH
processor = bundle.get_text_processor()
tacotron2 = bundle.get_tacotron2().to(device)
vocoder = bundle.get_vocoder().to(device)
with torch.inference_mode():
processed, lengths = processor(text)
processed = processed.to(device)
lengths = lengths.to(device)
spec, spec_lengths, _ = tacotron2.infer(processed, lengths)
waveforms, lengths = vocoder(spec, spec_lengths)
/pytorch/audio/ci_env/lib/python3.10/site-packages/dp/model/model.py:306: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
checkpoint = torch.load(checkpoint_path, map_location=device)
/pytorch/audio/ci_env/lib/python3.10/site-packages/torch/nn/modules/transformer.py:379: UserWarning: enable_nested_tensor is True, but self.use_nested_tensor is False because encoder_layer.self_attn.batch_first was not True(use batch_first for better inference performance)
warnings.warn(
Downloading: "https://download.pytorch.org/torchaudio/models/tacotron2_english_phonemes_1500_epochs_ljspeech.pth" to /root/.cache/torch/hub/checkpoints/tacotron2_english_phonemes_1500_epochs_ljspeech.pth
0%| | 0.00/107M [00:00<?, ?B/s]
14%|#3 | 14.9M/107M [00:00<00:01, 65.9MB/s]
20%|#9 | 21.2M/107M [00:00<00:01, 54.3MB/s]
30%|##9 | 32.0M/107M [00:00<00:01, 60.0MB/s]
44%|####3 | 46.9M/107M [00:00<00:01, 60.9MB/s]
49%|####8 | 52.6M/107M [00:01<00:01, 38.2MB/s]
59%|#####8 | 63.2M/107M [00:01<00:00, 50.0MB/s]
65%|######4 | 69.8M/107M [00:01<00:00, 46.5MB/s]
74%|#######4 | 80.0M/107M [00:01<00:00, 48.0MB/s]
88%|########8 | 94.9M/107M [00:01<00:00, 59.6MB/s]
94%|#########4| 101M/107M [00:02<00:00, 39.2MB/s]
99%|#########8| 106M/107M [00:02<00:00, 38.5MB/s]
100%|##########| 107M/107M [00:02<00:00, 42.2MB/s]
Waveglow 聲碼器¶
Waveglow 是 Nvidia 釋出的一種聲碼器。預訓練權重發布在 Torch Hub 上。可以使用 torch.hub 模組例項化該模型。
# Workaround to load model mapped on GPU
# https://stackoverflow.com/a/61840832
waveglow = torch.hub.load(
"NVIDIA/DeepLearningExamples:torchhub",
"nvidia_waveglow",
model_math="fp32",
pretrained=False,
)
checkpoint = torch.hub.load_state_dict_from_url(
"https://api.ngc.nvidia.com/v2/models/nvidia/waveglowpyt_fp32/versions/1/files/nvidia_waveglowpyt_fp32_20190306.pth", # noqa: E501
progress=False,
map_location=device,
)
state_dict = {key.replace("module.", ""): value for key, value in checkpoint["state_dict"].items()}
waveglow.load_state_dict(state_dict)
waveglow = waveglow.remove_weightnorm(waveglow)
waveglow = waveglow.to(device)
waveglow.eval()
with torch.no_grad():
waveforms = waveglow.infer(spec)
/pytorch/audio/ci_env/lib/python3.10/site-packages/torch/hub.py:330: UserWarning: You are about to download and run code from an untrusted repository. In a future release, this won't be allowed. To add the repository to your trusted list, change the command to {calling_fn}(..., trust_repo=False) and a command prompt will appear asking for an explicit confirmation of trust, or load(..., trust_repo=True), which will assume that the prompt is to be answered with 'yes'. You can also use load(..., trust_repo='check') which will only prompt for confirmation if the repo is not already trusted. This will eventually be the default behaviour
warnings.warn(
Downloading: "https://github.com/NVIDIA/DeepLearningExamples/zipball/torchhub" to /root/.cache/torch/hub/torchhub.zip
/root/.cache/torch/hub/NVIDIA_DeepLearningExamples_torchhub/PyTorch/Classification/ConvNets/image_classification/models/common.py:13: UserWarning: pytorch_quantization module not found, quantization will not be available
warnings.warn(
/root/.cache/torch/hub/NVIDIA_DeepLearningExamples_torchhub/PyTorch/Classification/ConvNets/image_classification/models/efficientnet.py:17: UserWarning: pytorch_quantization module not found, quantization will not be available
warnings.warn(
/pytorch/audio/ci_env/lib/python3.10/site-packages/torch/nn/utils/weight_norm.py:143: FutureWarning: `torch.nn.utils.weight_norm` is deprecated in favor of `torch.nn.utils.parametrizations.weight_norm`.
WeightNorm.apply(module, name, dim)
Downloading: "https://api.ngc.nvidia.com/v2/models/nvidia/waveglowpyt_fp32/versions/1/files/nvidia_waveglowpyt_fp32_20190306.pth" to /root/.cache/torch/hub/checkpoints/nvidia_waveglowpyt_fp32_20190306.pth
指令碼總執行時間: ( 1 分 13.712 秒)
