


注意
點選 此處 下載完整示例程式碼
振盪器與ADSR包絡¶
作者: Moto Hira
本教程演示如何使用 oscillator_bank() 和 adsr_envelope() 合成各種波形。
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
2.7.0
2.7.0
try:
from torchaudio.prototype.functional import adsr_envelope, oscillator_bank
except ModuleNotFoundError:
print(
"Failed to import prototype DSP features. "
"Please install torchaudio nightly builds. "
"Please refer to https://pytorch.com.tw/get-started/locally "
"for instructions to install a nightly build."
)
raise
import math
import matplotlib.pyplot as plt
from IPython.display import Audio
PI = torch.pi
PI2 = 2 * torch.pi
振盪器組¶
正弦振盪器根據給定的幅度和頻率生成正弦波形。
其中相位 \(\theta_t\) 是透過對瞬時頻率 \(f_t\) 進行積分得到的。
注意
為什麼對頻率進行積分?瞬時頻率表示給定時刻的振盪速度。因此,對瞬時頻率進行積分可以得到振盪相位自開始以來的位移。在離散時間訊號處理中,積分變為累加。在 PyTorch 中,累加可以使用 torch.cumsum() 計算。
torchaudio.prototype.functional.oscillator_bank() 根據幅度包絡和瞬時頻率生成一組正弦波形。
簡單正弦波¶
讓我們從簡單的例子開始。
首先,我們生成在任何地方具有恆定頻率和幅度的正弦波,即一個標準正弦波。
我們定義一些常數和輔助函式,用於本教程的其餘部分。
F0 = 344.0 # fundamental frequency
DURATION = 1.1 # [seconds]
SAMPLE_RATE = 16_000 # [Hz]
NUM_FRAMES = int(DURATION * SAMPLE_RATE)
def show(freq, amp, waveform, sample_rate, zoom=None, vol=0.3):
t = (torch.arange(waveform.size(0)) / sample_rate).numpy()
fig, axes = plt.subplots(4, 1, sharex=True)
axes[0].plot(t, freq.numpy())
axes[0].set(title=f"Oscillator bank (bank size: {amp.size(-1)})", ylabel="Frequency [Hz]", ylim=[-0.03, None])
axes[1].plot(t, amp.numpy())
axes[1].set(ylabel="Amplitude", ylim=[-0.03 if torch.all(amp >= 0.0) else None, None])
axes[2].plot(t, waveform.numpy())
axes[2].set(ylabel="Waveform")
axes[3].specgram(waveform, Fs=sample_rate)
axes[3].set(ylabel="Spectrogram", xlabel="Time [s]", xlim=[-0.01, t[-1] + 0.01])
for i in range(4):
axes[i].grid(True)
pos = axes[2].get_position()
plt.tight_layout()
if zoom is not None:
ax = fig.add_axes([pos.x0 + 0.01, pos.y0 + 0.03, pos.width / 2.5, pos.height / 2.0])
ax.plot(t, waveform)
ax.set(xlim=zoom, xticks=[], yticks=[])
waveform /= waveform.abs().max()
return Audio(vol * waveform, rate=sample_rate, normalize=False)
現在我們合成具有恆定頻率和幅度的音訊
freq = torch.full((NUM_FRAMES, 1), F0)
amp = torch.ones((NUM_FRAMES, 1))
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE, zoom=(1 / F0, 3 / F0))
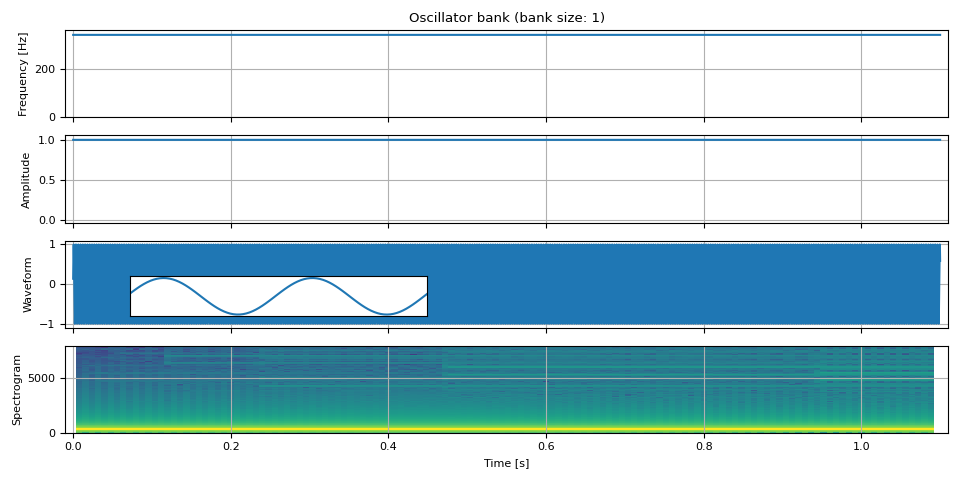
組合多個正弦波¶
oscillator_bank() 可以組合任意數量的正弦波以生成波形。
freq = torch.empty((NUM_FRAMES, 3))
freq[:, 0] = F0
freq[:, 1] = 3 * F0
freq[:, 2] = 5 * F0
amp = torch.ones((NUM_FRAMES, 3)) / 3
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE, zoom=(1 / F0, 3 / F0))
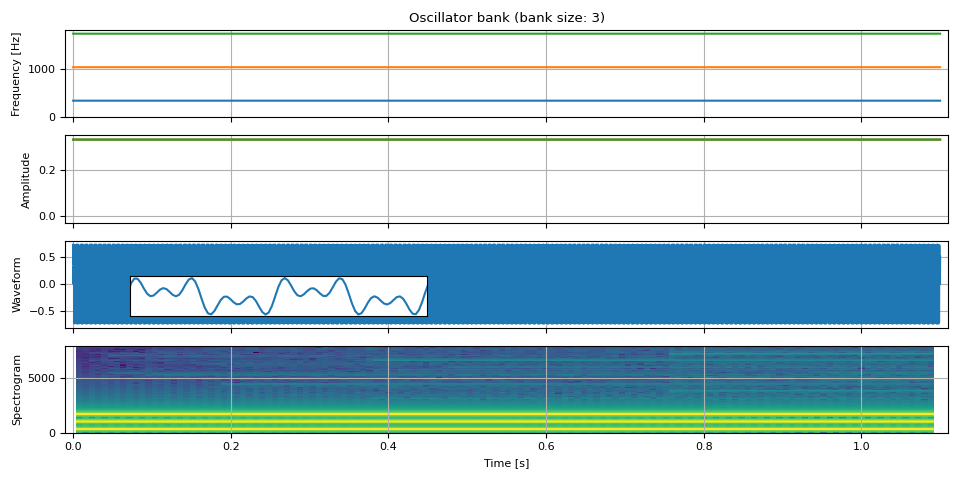
隨時間改變頻率¶
讓我們隨時間改變頻率。在這裡,我們將頻率從零到奈奎斯特頻率(取樣率的一半)在對數尺度上變化,以便容易看出波形的變化。
nyquist_freq = SAMPLE_RATE / 2
freq = torch.logspace(0, math.log(0.99 * nyquist_freq, 10), NUM_FRAMES).unsqueeze(-1)
amp = torch.ones((NUM_FRAMES, 1))
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE, vol=0.2)
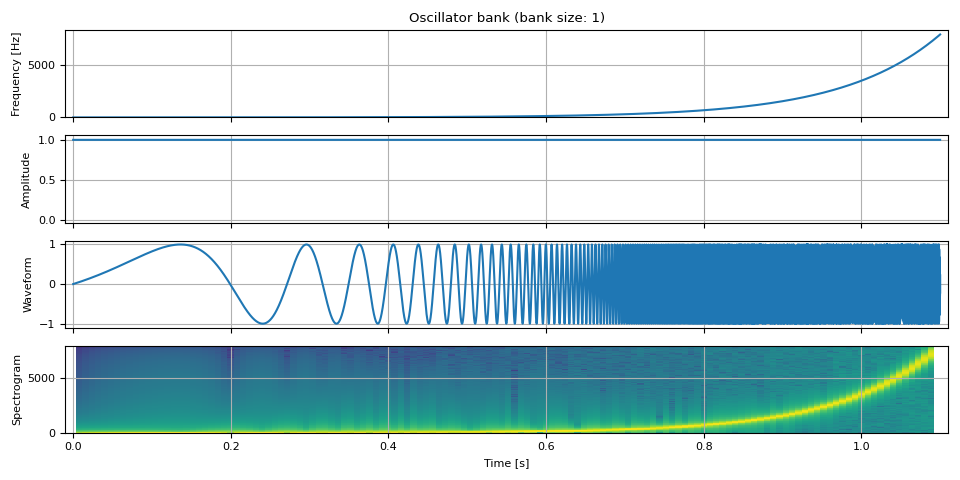
我們也可以使頻率振盪。
fm = 2.5 # rate at which the frequency oscillates
f_dev = 0.9 * F0 # the degree of frequency oscillation
freq = F0 + f_dev * torch.sin(torch.linspace(0, fm * PI2 * DURATION, NUM_FRAMES))
freq = freq.unsqueeze(-1)
amp = torch.ones((NUM_FRAMES, 1))
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE)
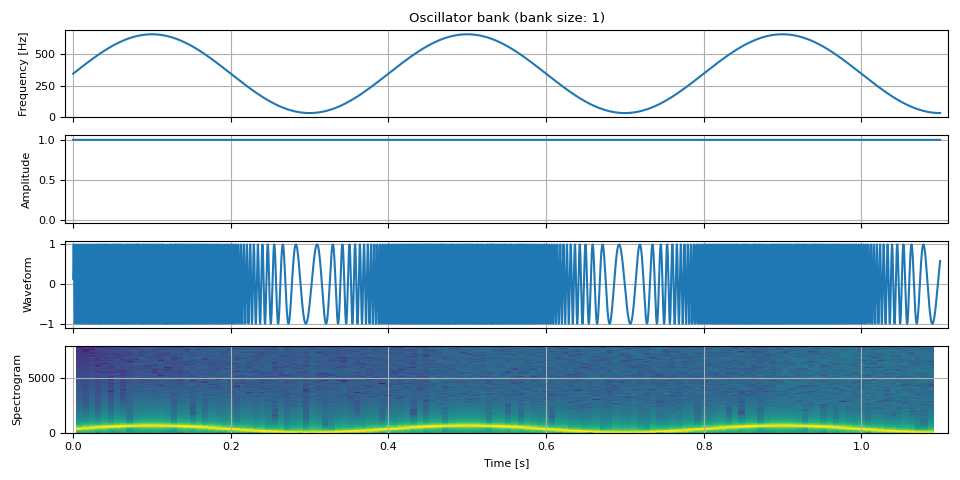
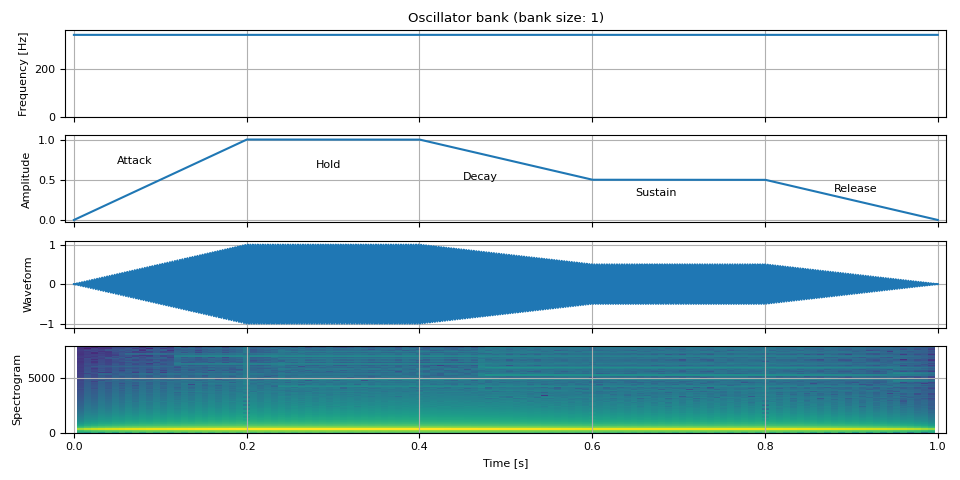
ADSR 包絡¶
接下來,我們隨時間改變幅度。一種常見的幅度建模技術是 ADSR 包絡。
ADSR 代表 啟動 (Attack)、衰減 (Decay)、延音 (Sustain) 和 釋音 (Release)。
啟動 (Attack) 是從零到達最高級別所需的時間。
衰減 (Decay) 是從最高級別到達延音級別所需的時間。
延音 (Sustain) 是級別保持不變的水平。
釋音 (Release) 是從延音級別降至零所需的時間。
ADSR 模型有許多變體,此外,一些模型還具有以下屬性
保持 (Hold):啟動後級別停留在最高級別的時間。
非線性衰減/釋音:衰減和釋音採用非線性變化。
adsr_envelope 支援保持和多項式衰減。
freq = torch.full((SAMPLE_RATE, 1), F0)
amp = adsr_envelope(
SAMPLE_RATE,
attack=0.2,
hold=0.2,
decay=0.2,
sustain=0.5,
release=0.2,
n_decay=1,
)
amp = amp.unsqueeze(-1)
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
audio = show(freq, amp, waveform, SAMPLE_RATE)
ax = plt.gcf().axes[1]
ax.annotate("Attack", xy=(0.05, 0.7))
ax.annotate("Hold", xy=(0.28, 0.65))
ax.annotate("Decay", xy=(0.45, 0.5))
ax.annotate("Sustain", xy=(0.65, 0.3))
ax.annotate("Release", xy=(0.88, 0.35))
audio
現在讓我們看一些例子,瞭解如何使用 ADSR 包絡建立不同的聲音。
以下示例受到 這篇文章 的啟發。
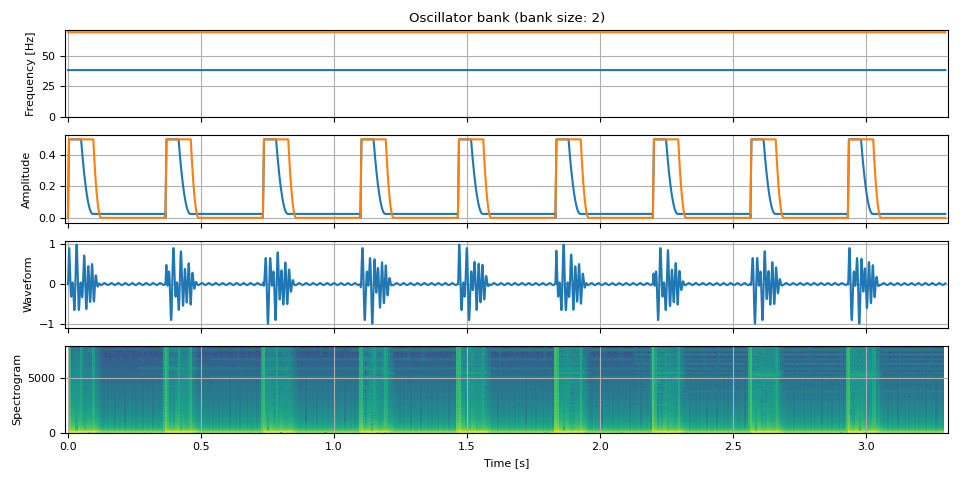
鼓點¶
unit = NUM_FRAMES // 3
repeat = 9
freq = torch.empty((unit * repeat, 2))
freq[:, 0] = F0 / 9
freq[:, 1] = F0 / 5
amp = torch.stack(
(
adsr_envelope(unit, attack=0.01, hold=0.125, decay=0.12, sustain=0.05, release=0),
adsr_envelope(unit, attack=0.01, hold=0.25, decay=0.08, sustain=0, release=0),
),
dim=-1,
)
amp = amp.repeat(repeat, 1) / 2
bass = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, bass, SAMPLE_RATE, vol=0.5)
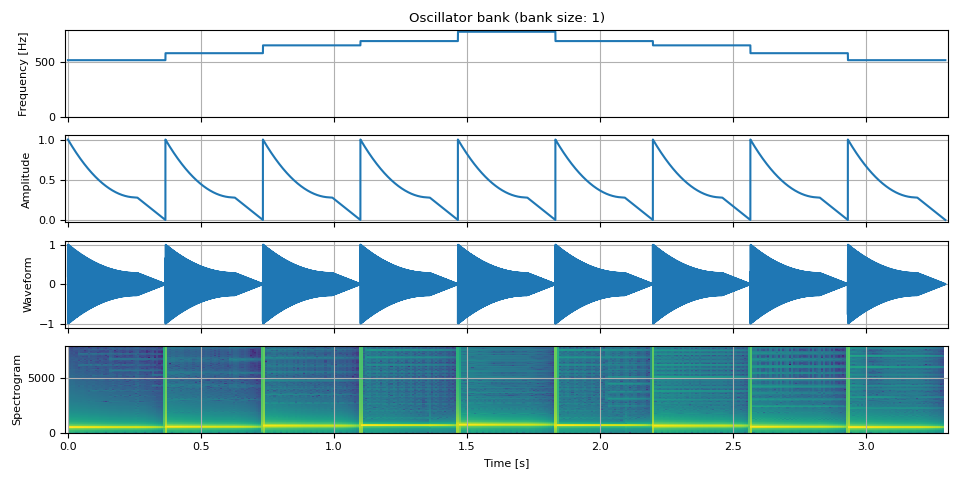
撥絃¶
tones = [
513.74, # do
576.65, # re
647.27, # mi
685.76, # fa
769.74, # so
685.76, # fa
647.27, # mi
576.65, # re
513.74, # do
]
freq = torch.cat([torch.full((unit, 1), tone) for tone in tones], dim=0)
amp = adsr_envelope(unit, attack=0, decay=0.7, sustain=0.28, release=0.29)
amp = amp.repeat(9).unsqueeze(-1)
doremi = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, doremi, SAMPLE_RATE)
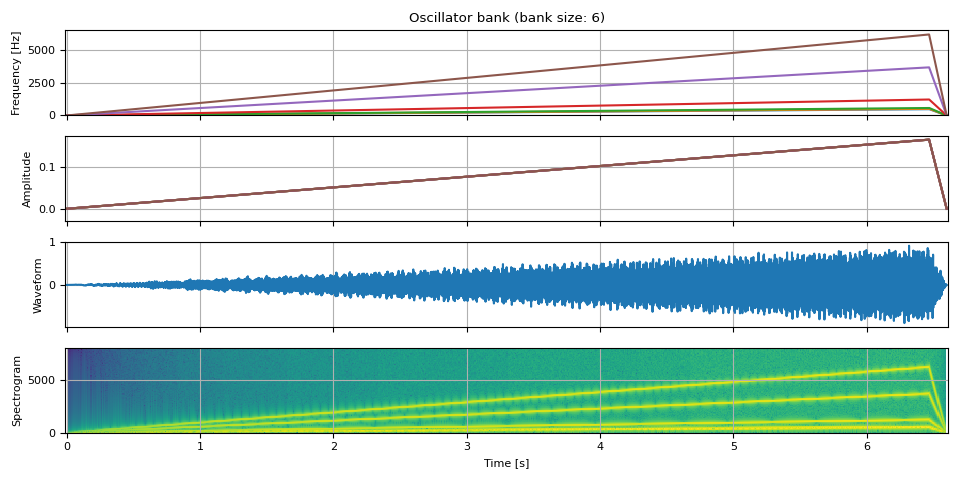
漸強¶
env = adsr_envelope(NUM_FRAMES * 6, attack=0.98, decay=0.0, sustain=1, release=0.02)
tones = [
484.90, # B4
513.74, # C5
576.65, # D5
1221.88, # D#6/Eb6
3661.50, # A#7/Bb7
6157.89, # G8
]
freq = torch.stack([f * env for f in tones], dim=-1)
amp = env.unsqueeze(-1).expand(freq.shape) / len(tones)
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
show(freq, amp, waveform, SAMPLE_RATE)
參考資料¶
指令碼總執行時間: ( 0 分 3.041 秒)
