torchrl.data 包¶
重放緩衝區 (Replay Buffers)¶
重放緩衝區是非策略強化學習 (off-policy RL) 演算法的核心組成部分。TorchRL 提供了一些常用重放緩衝區的高效實現。
|
一個通用的、可組合的重放緩衝區類。 |
|
優先重放緩衝區。 |
|
圍繞 |
|
圍繞 |
可組合重放緩衝區¶
我們還為使用者提供了組合重放緩衝區的能力。我們提供了廣泛的重放緩衝區使用解決方案,包括支援幾乎任何資料型別;記憶體、裝置或物理記憶體中的儲存;多種取樣策略;transforms 的使用等。
支援的資料型別和儲存選擇¶
理論上,重放緩衝區支援任何資料型別,但我們無法保證每個元件都支援任何資料型別。最原始的重放緩衝區實現是由一個 ReplayBuffer 基類和一個 ListStorage 儲存組成。這種方式效率非常低,但允許你儲存包含非 tensor 資料的複雜資料結構。連續記憶體中的儲存包括 TensorStorage、LazyTensorStorage 和 LazyMemmapStorage。這些類將 TensorDict 資料作為一等公民支援,但也支援任何 PyTree 資料結構(例如,元組、列表、字典及其巢狀版本)。TensorStorage 儲存要求你在構建時提供儲存,而 TensorStorage(RAM,CUDA)和 LazyMemmapStorage(物理記憶體)在首次擴充套件後會為你預分配儲存。
以下是一些示例,從通用的 ListStorage 開始
>>> from torchrl.data.replay_buffers import ReplayBuffer, ListStorage
>>> rb = ReplayBuffer(storage=ListStorage(10))
>>> rb.add("a string!") # first element will be a string
>>> rb.extend([30, None]) # element [1] is an int, [2] is None
寫入緩衝區的主要入口點是 add() 和 extend()。也可以使用 __setitem__(),在這種情況下,資料會按指示寫入,而不會更新緩衝區的長度或遊標。這在從緩衝區中取樣專案並在之後原地更新其值時非常有用。
使用 TensorStorage 時,我們告訴 RB 我們希望儲存是連續的,這無疑效率更高,但也更具限制性。
>>> import torch
>>> from torchrl.data.replay_buffers import ReplayBuffer, TensorStorage
>>> container = torch.empty(10, 3, 64, 64, dtype=torch.unit8)
>>> rb = ReplayBuffer(storage=TensorStorage(container))
>>> img = torch.randint(255, (3, 64, 64), dtype=torch.uint8)
>>> rb.add(img)
接下來,我們可以避免建立容器,並讓儲存自動建立它。這在使用 PyTrees 和 tensordicts 時非常有用!對於 PyTrees 等資料結構,add() 將傳遞給它的樣本視為該型別的單個例項。extend() 則會將資料視為一個可迭代物件。對於 tensors、tensordicts 和列表(見下文),可迭代物件會在根級別查詢。對於 PyTrees,我們假設樹中所有葉子(tensors)的前導維度是匹配的。如果不匹配,extend 將丟擲異常。
>>> import torch
>>> from tensordict import TensorDict
>>> from torchrl.data.replay_buffers import ReplayBuffer, LazyMemmapStorage
>>> rb_td = ReplayBuffer(storage=LazyMemmapStorage(10), batch_size=1) # max 10 elements stored
>>> rb_td.add(TensorDict({"img": torch.randint(255, (3, 64, 64), dtype=torch.unit8),
... "labels": torch.randint(100, ())}, batch_size=[]))
>>> rb_pytree = ReplayBuffer(storage=LazyMemmapStorage(10)) # max 10 elements stored
>>> # extend with a PyTree where all tensors have the same leading dim (3)
>>> rb_pytree.extend({"a": {"b": torch.randn(3), "c": [torch.zeros(3, 2), (torch.ones(3, 10),)]}})
>>> assert len(rb_pytree) == 3 # the replay buffer has 3 elements!
注意
extend() 在處理值列表時可能存在簽名模糊,這應該被解釋為 PyTree(在這種情況下,列表中的所有元素將被放入儲存中儲存的 PyTree 的一個切片中),或被解釋為需要逐個新增的值列表。為了解決這個問題,TorchRL 在 list 和 tuple 之間做了明確的區分:tuple 將被視為一個 PyTree,而列表(在根級別)將被解釋為需要逐個新增到緩衝區的值棧。
取樣和索引¶
重放緩衝區可以被索引和取樣。索引和取樣會在儲存中的給定索引處收集資料,然後透過一系列 transforms 和 collate_fn 進行處理,這些可以傳遞給重放緩衝區的 __init__ 函式。collate_fn 帶有預設值,這些預設值在大多數情況下應與使用者的預期相符,因此大多數時候你無需為此擔心。Transforms 通常是 Transform 的例項,儘管常規函式也可以工作(在後一種情況下,inv() 方法顯然會被忽略,而在前一種情況下,它可用於在資料傳遞到緩衝區之前進行預處理)。最後,可以透過將執行緒數透過 prefetch 關鍵字引數傳遞給建構函式來使用多執行緒實現取樣。我們建議使用者在實際設定中對這項技術進行基準測試後再採用,因為不能保證它在實踐中一定能帶來更快的吞吐量,這取決於使用的機器和設定。
取樣時,batch_size 可以在構建時傳遞(例如,如果在整個訓練過程中保持不變),也可以傳遞給 sample() 方法。
為了進一步細化取樣策略,我們建議你檢視我們的 samplers!
以下是一些從重放緩衝區獲取資料的示例
>>> first_elt = rb_td[0]
>>> storage = rb_td[:] # returns all valid elements from the buffer
>>> sample = rb_td.sample(128)
>>> for data in rb_td: # iterate over the buffer using the sampler -- batch-size was set in the constructor to 1
... print(data)
使用以下元件
|
以緊湊形式儲存儲存,節省 TED 格式的空間。 |
|
以緊湊形式儲存儲存,節省 TED 格式的空間,並使用 H5 格式儲存資料。 |
|
用於不可變資料集的阻塞寫入器。 |
|
用於 tensors 和 tensordicts 的記憶體對映儲存。 |
|
用於 tensors 和 tensordicts 的預分配 tensor 儲存。 |
|
儲存在列表中的儲存。 |
|
返回 LazyStackTensorDict 例項的 ListStorage。 |
用於 ListStorage 的儲存檢查點。 |
|
|
以緊湊形式儲存儲存,節省 TED 格式的空間,並使用記憶體對映巢狀 tensors。 |
|
重放緩衝區的優先採樣器。 |
|
根據開始和停止訊號,沿第一個維度取樣資料切片,使用優先採樣。 |
可組合重放緩衝區的均勻隨機取樣器。 |
|
|
可組合重放緩衝區的 RoundRobin 寫入器類。 |
|
可組合重放緩衝區的通用取樣器基類。 |
|
一種消耗資料的取樣器,確保同一樣本不會出現在連續的批次中。 |
|
根據開始和停止訊號,沿第一個維度取樣資料切片。 |
|
根據開始和停止訊號,沿第一個維度進行無放回取樣資料切片。 |
|
Storage 是重放緩衝區的容器。 |
儲存檢查點器的公共基類。 |
|
集合儲存的檢查點器。 |
|
|
可組合重放緩衝區的寫入器類,根據某個排名鍵保留頂部元素。 |
|
可組合的、基於 tensordict 的重放緩衝區的 RoundRobin 寫入器類。 |
|
用於 tensors 和 tensordicts 的儲存。 |
用於 TensorStorages 的儲存檢查點。 |
|
|
重放緩衝區基礎寫入器類。 |
儲存選擇對重放緩衝區的取樣延遲影響很大,尤其是在資料量較大的分散式強化學習設定中。LazyMemmapStorage 在具有共享儲存的分散式設定中非常推薦,因為它具有較低的 MemoryMappedTensors 序列化開銷,並且能夠指定檔案儲存位置以改善節點故障恢復。在 https://github.com/pytorch/rl/tree/main/benchmarks/storage 的粗略基準測試中,發現了相對於使用 ListStorage 的以下平均取樣延遲改進。
儲存型別 |
加速比 |
|---|---|
1倍 |
|
1.83倍 |
|
3.44倍 |
儲存軌跡¶
將軌跡儲存在重放緩衝區中並不太困難。需要注意的一點是,重放緩衝區的大小預設是儲存前導維度的大小:換句話說,當儲存多維資料時,建立一個大小為 1M 的儲存重放緩衝區並不意味著儲存 1M 幀,而是 1M 條軌跡。然而,如果軌跡(或 episode/rollout)在儲存前被展平,容量仍將是 1M 步。
有一種方法可以規避這個問題,即告訴儲存在儲存資料時應該考慮多少個維度。這可以透過 ndim 關鍵字引數來實現,所有連續儲存(如 TensorStorage 等)都接受此引數。當多維儲存傳遞給緩衝區時,緩衝區會自動將最後一個維度視為“時間”維度,這在 TorchRL 中是慣例。這可以透過 ReplayBuffer 中的 dim_extend 關鍵字引數來覆蓋。這是儲存透過 ParallelEnv 或其序列對應項獲得的軌跡的推薦方法,我們將在下文看到。
取樣軌跡時,可能需要取樣子軌跡以使學習多樣化或提高取樣效率。TorchRL 提供了兩種獨特的方法來實現這一點
透過
SliceSampler可以取樣儲存在TensorStorage前導維度中,一個接一個排列的軌跡的指定數量的切片。這是 TorchRL 中取樣子軌跡的推薦方法,__尤其是在使用離線資料集__(使用該約定儲存)時。此策略要求在擴充套件重放緩衝區之前展平軌跡,並在取樣後重塑它們。SliceSampler類的文件字串提供了關於此儲存和取樣策略的詳細資訊。請注意,SliceSampler與多維儲存相容。以下示例展示瞭如何使用此功能,以及是否對 tensordict 進行展平。在第一個場景中,我們從單個環境收集資料。在這種情況下,我們很高興使用一個沿第一個維度連線傳入資料的儲存,因為收集計劃不會引入中斷。>>> from torchrl.envs import TransformedEnv, StepCounter, GymEnv >>> from torchrl.collectors import SyncDataCollector, RandomPolicy >>> from torchrl.data import ReplayBuffer, LazyTensorStorage, SliceSampler >>> env = TransformedEnv(GymEnv("CartPole-v1"), StepCounter()) >>> collector = SyncDataCollector(env, ... RandomPolicy(env.action_spec), ... frames_per_batch=10, total_frames=-1) >>> rb = ReplayBuffer( ... storage=LazyTensorStorage(100), ... sampler=SliceSampler(num_slices=8, traj_key=("collector", "traj_ids"), ... truncated_key=None, strict_length=False), ... batch_size=64) >>> for i, data in enumerate(collector): ... rb.extend(data) ... if i == 10: ... break >>> assert len(rb) == 100, len(rb) >>> print(rb[:]["next", "step_count"]) tensor([[32], [33], [34], [35], [36], [37], [38], [39], [40], [41], [11], [12], [13], [14], [15], [16], [17], [...
如果在一個批次中運行了多個環境,我們仍然可以透過呼叫
data.reshape(-1)將大小為[B, T]的資料展平為[B * T],並像之前一樣儲存在同一個緩衝區中,但這會意味著批次中第一個環境的軌跡將與其他環境的軌跡交錯,SliceSampler無法處理這種情況。為了解決這個問題,我們建議在儲存建構函式中使用ndim引數。>>> env = TransformedEnv(SerialEnv(2, ... lambda: GymEnv("CartPole-v1")), StepCounter()) >>> collector = SyncDataCollector(env, ... RandomPolicy(env.action_spec), ... frames_per_batch=1, total_frames=-1) >>> rb = ReplayBuffer( ... storage=LazyTensorStorage(100, ndim=2), ... sampler=SliceSampler(num_slices=8, traj_key=("collector", "traj_ids"), ... truncated_key=None, strict_length=False), ... batch_size=64) >>> for i, data in enumerate(collector): ... rb.extend(data) ... if i == 100: ... break >>> assert len(rb) == 100, len(rb) >>> print(rb[:]["next", "step_count"].squeeze()) tensor([[ 6, 5], [ 2, 2], [ 3, 3], [ 4, 4], [ 5, 5], [ 6, 6], [ 7, 7], [ 8, 8], [ 9, 9], [10, 10], [11, 11], [12, 12], [13, 13], [14, 14], [15, 15], [16, 16], [17, 17], [18, 1], [19, 2], [...
軌跡也可以獨立儲存,前導維度的每個元素指向不同的軌跡。這要求軌跡具有一致的形狀(或進行填充)。我們提供了一個名為
RandomCropTensorDict的自定義Transform類,它允許在緩衝區中取樣子軌跡。請注意,與基於SliceSampler的策略不同,這裡不需要有一個指向開始和停止訊號的"episode"或"done"鍵。以下是此類的使用示例
重放緩衝區檢查點¶
重放緩衝區的每個元件可能是有狀態的,因此需要一種專門的方法來對其進行序列化。我們的重放緩衝區提供了兩個獨立的 API 用於將其狀態儲存到磁碟:dumps() 和 loads() 將使用記憶體對映 tensors 和 json 檔案儲存除 transforms 外的每個元件(儲存、寫入器、取樣器)的資料和元資料。
這適用於除 ListStorage 之外的所有類,因為其內容無法預測(因此不符合 tensordict 庫中可以找到的記憶體對映資料結構)。
此 API 保證儲存後重新載入的緩衝區將處於完全相同的狀態,無論我們檢視其取樣器(例如,優先樹)、寫入器(例如,最大寫入堆)或儲存的狀態如何。
在底層,對 dumps() 的簡單呼叫將僅呼叫其每個元件(transforms 除外,我們通常不假設它們可以使用記憶體對映 tensors 進行序列化)在特定資料夾中的公共 dumps 方法。
然而,以 TED 格式儲存資料可能會消耗比所需更多的記憶體。如果連續的軌跡儲存在緩衝區中,我們可以透過儲存根級別所有 observation 以及僅儲存“next”子 tensordict 中 observation 的最後一個元素來避免儲存重複的 observation,這可以將儲存消耗減少多達兩倍。為了實現這一點,提供了三種檢查點類:FlatStorageCheckpointer 將丟棄重複的 observation 以壓縮 TED 格式。在載入時,此類將以正確格式重新寫入 observation。如果緩衝區儲存到磁碟,此檢查點執行的操作將不需要任何額外的 RAM。NestedStorageCheckpointer 將使用巢狀 tensors 儲存軌跡,以使資料表示更明顯(沿第一個維度的每個專案代表一個不同的軌跡)。最後,H5StorageCheckpointer 將以 H5DB 格式儲存緩衝區,使使用者能夠壓縮資料並節省更多空間。
警告
檢查點對經驗回放緩衝區做了一些限制性假設。首先,假設 done 狀態準確表示軌跡的結束(除了正在寫入的最後一條軌跡,其寫入遊標指示截斷訊號應放置的位置)。對於 MARL 用法,需要注意的是,只允許 done 狀態具有與根 Tensordict 相同數量的元素:如果 done 狀態具有儲存的批次大小中未表示的額外元素,這些檢查點將失敗。例如,在形狀為 torch.Size([3, 4]) 的儲存中,不允許形狀為 torch.Size([3, 4, 5]) 的 done 狀態。
下面是如何在實踐中使用 H5DB 檢查點的具體示例
>>> from torchrl.data import ReplayBuffer, H5StorageCheckpointer, LazyMemmapStorage
>>> from torchrl.collectors import SyncDataCollector
>>> from torchrl.envs import GymEnv, SerialEnv
>>> import torch
>>> env = SerialEnv(3, lambda: GymEnv("CartPole-v1", device=None))
>>> env.set_seed(0)
>>> torch.manual_seed(0)
>>> collector = SyncDataCollector(
>>> env, policy=env.rand_step, total_frames=200, frames_per_batch=22
>>> )
>>> rb = ReplayBuffer(storage=LazyMemmapStorage(100, ndim=2))
>>> rb_test = ReplayBuffer(storage=LazyMemmapStorage(100, ndim=2))
>>> rb.storage.checkpointer = H5StorageCheckpointer()
>>> rb_test.storage.checkpointer = H5StorageCheckpointer()
>>> for i, data in enumerate(collector):
... rb.extend(data)
... assert rb._storage.max_size == 102
... rb.dumps(path_to_save_dir)
... rb_test.loads(path_to_save_dir)
... assert_allclose_td(rb_test[:], rb[:])
每當無法使用 dumps() 儲存資料時,另一種方法是使用 state_dict(),它返回一個可以使用 torch.save() 儲存,然後在使用 load_state_dict() 之前使用 torch.load() 載入的資料結構。這種方法的缺點是很難儲存大型資料結構,這在使用經驗回放緩衝區時是一個常見情況。
TorchRL 幕資料格式 (TED)¶
在 TorchRL 中,序列資料始終以特定格式呈現,稱為 TorchRL 幕資料格式 (TED)。這種格式對於 TorchRL 中各種元件的無縫整合和執行至關重要。
某些元件,例如經驗回放緩衝區,對資料格式有些不敏感。然而,其他元件,特別是環境,則高度依賴於它以實現平穩執行。
因此,瞭解 TED、其用途以及如何與其互動至關重要。本指南將清晰解釋 TED、為何使用它以及如何有效地與其協作。
TED 背後的原理¶
格式化序列資料可能是一項複雜的任務,尤其是在強化學習 (RL) 領域。作為實踐者,我們經常遇到在重置時(儘管並非總是如此)交付資料的情況,有時資料會在軌跡的最後一步提供或丟棄。
這種可變性意味著我們可以在資料集中觀察到不同長度的資料,並且並不總是立即清楚如何匹配此資料集各種元素中的每個時間步。考慮以下模糊的資料集結構
>>> observation.shape
[200, 3]
>>> action.shape
[199, 4]
>>> info.shape
[200, 3]
乍一看,似乎 info 和 observation 是同時交付的(重置時各有一次 + 每次 step 呼叫時各有一次),正如 action 元素少一個所暗示的那樣。然而,如果 info 元素少一個,我們必須假設它要麼在重置時被省略,要麼在軌跡的最後一步未交付或未記錄。如果沒有適當的資料結構文件,就無法確定哪個 info 對應哪個時間步。
更復雜的是,某些資料集提供的資料格式不一致,其中 observations 或 infos 在 rollout 的開始或結束時缺失,並且這種行為通常沒有文件說明。TED 的主要目標是透過提供清晰一致的資料表示來消除這些歧義。
TED 的結構¶
TED 構建在 RL 上下文中馬爾可夫決策過程 (MDP) 的規範定義之上。在每一步中,一個 observation 條件化一個 action,該 action 會產生 (1) 一個新的 observation,(2) 一個任務完成指示器(終止、截斷、完成),以及 (3) 一個獎勵訊號。
某些元素可能缺失(例如,獎勵在模仿學習上下文中是可選的),或者可以透過狀態或資訊容器傳遞附加資訊。在某些情況下,為了在呼叫 step 期間獲取 observation,需要附加資訊(例如,在無狀態環境模擬器中)。此外,在某些場景中,“action”(或任何其他資料)無法表示為單個張量,需要以不同方式組織。例如,在多智慧體強化學習設定中,actions、observations、rewards 和完成訊號可能是複合的。
TED 以單一、統一、明確的格式適應所有這些場景。我們透過設定 action 執行的時間來區分時間步 t 和 t+1 之間發生的事情。換句話說,在呼叫 env.step 之前存在的一切都屬於 t,而之後的一切都屬於 t+1。
一般規則是,屬於時間步 t 的所有內容都儲存在 Tensordict 的根目錄中,而屬於 t+1 的所有內容都儲存在 Tensordict 的 "next" 條目中。這裡有一個例子
>>> data = env.reset()
>>> data = policy(data)
>>> print(env.step(data))
TensorDict(
fields={
action: Tensor(...), # The action taken at time t
done: Tensor(...), # The done state when the action was taken (at reset)
next: TensorDict( # all of this content comes from the call to `step`
fields={
done: Tensor(...), # The done state after the action has been taken
observation: Tensor(...), # The observation resulting from the action
reward: Tensor(...), # The reward resulting from the action
terminated: Tensor(...), # The terminated state after the action has been taken
truncated: Tensor(...), # The truncated state after the action has been taken
batch_size=torch.Size([]),
device=cpu,
is_shared=False),
observation: Tensor(...), # the observation at reset
terminated: Tensor(...), # the terminated at reset
truncated: Tensor(...), # the truncated at reset
batch_size=torch.Size([]),
device=cpu,
is_shared=False)
在 rollout 期間(使用 EnvBase 或 SyncDataCollector),當智慧體重置其步數計數時,"next" Tensordict 的內容會透過 step_mdp() 函式被帶到根目錄:t <- t+1。您可以在這裡閱讀有關環境 API 的更多資訊。
在大多數情況下,根目錄沒有值為 True 的 "done" 狀態,因為任何 done 狀態都會觸發(部分)重置,這將使 "done" 變為 False。然而,這隻有在自動執行重置的情況下才成立。在某些情況下,部分重置不會觸發重置,因此我們保留這些資料,這些資料應該比 observations 等具有顯著低的記憶體佔用。
這種格式消除了 observation 與其 action、info 或 done 狀態匹配的任何歧義。
關於 TED 中單例維度的說明¶
在 TorchRL 中,標準做法是 done 狀態(包括 terminated 和 truncated)和獎勵應具有一個維度,該維度可以擴充套件以匹配 observations、states 和 actions 的形狀,而無需藉助重複以外的任何操作(即,獎勵必須與 observation 和/或 action 或它們的嵌入具有相同數量的維度)。
本質上,這種格式是可接受的(儘管並非嚴格強制執行)
>>> print(rollout[t])
... TensorDict(
... fields={
... action: Tensor(n_action),
... done: Tensor(1), # The done state has a rightmost singleton dimension
... next: TensorDict(
... fields={
... done: Tensor(1),
... observation: Tensor(n_obs),
... reward: Tensor(1), # The reward has a rightmost singleton dimension
... terminated: Tensor(1),
... truncated: Tensor(1),
... batch_size=torch.Size([]),
... device=cpu,
... is_shared=False),
... observation: Tensor(n_obs), # the observation at reset
... terminated: Tensor(1), # the terminated at reset
... truncated: Tensor(1), # the truncated at reset
... batch_size=torch.Size([]),
... device=cpu,
... is_shared=False)
這樣做的原因是為了確保對 observations 和/或 actions 進行操作(例如價值估計)的結果與獎勵和 done 狀態具有相同的維度數量。這種一致性使得後續操作能夠順利進行
>>> state_value = f(observation)
>>> next_state_value = state_value + reward
如果沒有獎勵末尾的這個單例維度,廣播規則(僅當張量可以從左側擴充套件時才起作用)會嘗試從左側擴充套件獎勵。這可能導致失敗(最好情況)或引入錯誤(最壞情況)。
展平 TED 以減少記憶體消耗¶
TED 在記憶體中複製 observation 兩次,這可能會影響在實踐中使用此格式的可行性。由於它主要用於方便表示,因此可以以扁平方式儲存資料,但在訓練期間將其表示為 TED。
這在序列化經驗回放緩衝區時特別有用:例如,TED2Flat 類確保在寫入磁碟之前將 TED 格式的資料結構展平,而 Flat2TED 載入鉤子將在反序列化期間對該結構進行解展平。
Tensordict 的維度¶
在 rollout 期間,所有收集到的 Tensordicts 將沿末尾新增的維度堆疊。收集器和環境都將使用 "time" 名稱標記此維度。這裡有一個例子
>>> rollout = env.rollout(10, policy)
>>> assert rollout.shape[-1] == 10
>>> assert rollout.names[-1] == "time"
這確保了時間維度在資料結構中被清晰標記且易於識別。
特殊情況和腳註¶
多智慧體資料表示¶
多智慧體資料格式文件可在多智慧體強化學習環境 API 部分訪問。
基於記憶的策略(RNNs 和 Transformers)¶
在上面提供的示例中,只有 env.step(data) 生成需要在下一步讀取的資料。然而,在某些情況下,策略也會輸出需要在下一步使用的資訊。這通常是基於 RNN 的策略的情況,它們輸出一個 action 以及需要在下一步使用的迴圈狀態。為了適應這種情況,我們建議使用者調整其 RNN 策略,將這些資料寫入 Tensordict 的 "next" 條目下。這確保了該內容將在下一步被帶到根目錄。更多資訊可在 GRUModule 和 LSTMModule 中找到。
多步¶
收集器允許使用者在讀取資料時跳過步驟,累積未來 n 個步驟的獎勵。這種技術在類似 DQN 的演算法(如 Rainbow)中很受歡迎。MultiStep 類對從收集器出來的批次執行此資料轉換。在這些情況下,由於下一個 observation 偏移了 n 個步驟,如下所示的檢查將失敗
>>> assert (data[..., 1:]["observation"] == data[..., :-1]["next", "observation"]).all()
記憶體需求如何?¶
天真地實現此資料格式會消耗大約扁平表示的兩倍記憶體。在某些記憶體密集型設定中(例如,在 AtariDQNExperienceReplay 資料集中),我們僅在磁碟上儲存 T+1 observation,並在獲取時線上執行格式化。在其他情況下,我們假設 2 倍記憶體成本是一個小代價,以便獲得更清晰的表示。然而,推廣離線資料集的惰性表示肯定會是一個有益的功能,我們歡迎在這方面的貢獻!
資料集¶
TorchRL 提供對離線強化學習資料集的包裝器。這些資料表示為 ReplayBuffer 例項,這意味著它們可以使用 transforms、samplers 和 storages 隨意自定義。例如,可以使用 SelectTransform 或 ExcludeTransform 從資料集中過濾出或過濾進條目。
預設情況下,資料集儲存為記憶體對映張量,允許它們快速取樣,幾乎沒有記憶體佔用。
這裡有一個例子
注意
安裝依賴項是使用者的責任。對於 D4RL,需要克隆此倉庫,因為最新的 wheel 包未釋出在 PyPI 上。對於 OpenML,需要 scikit-learn 和 pandas。
轉換資料集¶
在許多情況下,原始資料不會原樣使用。自然的解決方案可能是將 Transform 例項傳遞給資料集建構函式,並在執行時即時修改樣本。這將起作用,但會產生額外的 transform 執行時開銷。如果轉換可以(至少一部分)預應用到資料集,則可以節省大量磁碟空間和取樣時產生的一些開銷。為此,可以使用 preprocess() 方法。此方法將對資料集的每個元素執行一個按樣本的預處理管道,並用其轉換後的版本替換現有資料集。
一旦轉換,重新建立相同的資料集將產生另一個具有相同轉換後的儲存的物件(除非使用 download="force")
>>> dataset = RobosetExperienceReplay(
... "FK1-v4(expert)/FK1_MicroOpenRandom_v2d-v4", batch_size=32, download="force"
... )
>>>
>>> def func(data):
... return data.set("obs_norm", data.get("observation").norm(dim=-1))
...
>>> dataset.preprocess(
... func,
... num_workers=max(1, os.cpu_count() - 2),
... num_chunks=1000,
... mp_start_method="fork",
... )
>>> sample = dataset.sample()
>>> assert "obs_norm" in sample.keys()
>>> # re-recreating the dataset gives us the transformed version back.
>>> dataset = RobosetExperienceReplay(
... "FK1-v4(expert)/FK1_MicroOpenRandom_v2d-v4", batch_size=32
... )
>>> sample = dataset.sample()
>>> assert "obs_norm" in sample.keys()
|
離線資料集的父類。 |
|
Atari DQN 經驗回放類。 |
|
D4RL 的經驗回放類。 |
|
Gen-DGRL 經驗回放資料集。 |
|
Minari 經驗回放資料集。 |
|
OpenML 資料的經驗回放。 |
|
Open X-Embodiment 資料集經驗回放。 |
|
Roboset 經驗回放資料集。 |
|
V-D4RL 經驗回放資料集。 |
組合資料集¶
在離線強化學習中,同時使用多個數據集是慣例。此外,TorchRL 通常具有細粒度的資料集命名法,其中每個任務都單獨表示,而其他庫則以更緊湊的方式表示這些資料集。為了允許使用者將多個數據集組合在一起,我們提出了一個 ReplayBufferEnsemble 基本型別,允許使用者一次從多個數據集中取樣。
如果各個資料集格式不同,可以使用 Transform 例項。在以下示例中,我們建立了兩個虛擬資料集,它們的語義相同的條目名稱不同(("some", "key") 和 "another_key"),並演示如何重新命名它們以使其名稱匹配。我們還調整影像大小,以便它們可以在取樣期間堆疊在一起。
>>> from torchrl.envs import Comopse, ToTensorImage, Resize, RenameTransform
>>> from torchrl.data import TensorDictReplayBuffer, ReplayBufferEnsemble, LazyMemmapStorage
>>> from tensordict import TensorDict
>>> import torch
>>> rb0 = TensorDictReplayBuffer(
... storage=LazyMemmapStorage(10),
... transform=Compose(
... ToTensorImage(in_keys=["pixels", ("next", "pixels")]),
... Resize(32, in_keys=["pixels", ("next", "pixels")]),
... RenameTransform([("some", "key")], ["renamed"]),
... ),
... )
>>> rb1 = TensorDictReplayBuffer(
... storage=LazyMemmapStorage(10),
... transform=Compose(
... ToTensorImage(in_keys=["pixels", ("next", "pixels")]),
... Resize(32, in_keys=["pixels", ("next", "pixels")]),
... RenameTransform(["another_key"], ["renamed"]),
... ),
... )
>>> rb = ReplayBufferEnsemble(
... rb0,
... rb1,
... p=[0.5, 0.5],
... transform=Resize(33, in_keys=["pixels"], out_keys=["pixels33"]),
... )
>>> data0 = TensorDict(
... {
... "pixels": torch.randint(255, (10, 244, 244, 3)),
... ("next", "pixels"): torch.randint(255, (10, 244, 244, 3)),
... ("some", "key"): torch.randn(10),
... },
... batch_size=[10],
... )
>>> data1 = TensorDict(
... {
... "pixels": torch.randint(255, (10, 64, 64, 3)),
... ("next", "pixels"): torch.randint(255, (10, 64, 64, 3)),
... "another_key": torch.randn(10),
... },
... batch_size=[10],
... )
>>> rb[0].extend(data0)
>>> rb[1].extend(data1)
>>> for _ in range(2):
... sample = rb.sample(10)
... assert sample["next", "pixels"].shape == torch.Size([2, 5, 3, 32, 32])
... assert sample["pixels"].shape == torch.Size([2, 5, 3, 32, 32])
... assert sample["pixels33"].shape == torch.Size([2, 5, 3, 33, 33])
... assert sample["renamed"].shape == torch.Size([2, 5])
|
經驗回放緩衝區集合。 |
|
取樣器集合。 |
|
儲存集合。 |
|
寫入器集合。 |
TensorSpec¶
TensorSpec 父類及其子類定義了 TorchRL 中 state、observations action、rewards 和 done status 的基本屬性,例如它們的 shape、device、dtype 和 domain。
環境 specs 與其傳送和接收的輸入輸出匹配非常重要,因為 ParallelEnv 將根據這些 specs 建立緩衝區以與 spawn 程序通訊。請檢查 torchrl.envs.utils.check_env_specs() 方法進行健全性檢查。
如果需要,可以使用 make_composite_from_td() 函式從資料自動生成 specs。
Specs 主要分為數值型和類別型兩類。
數值型 |
|||
|---|---|---|---|
有界 |
無界 |
||
有界離散 |
有界連續 |
無界離散 |
無界連續 |
每當建立 Bounded 例項時,其域(由其 dtype 隱式定義或由 “domain” 關鍵字引數顯式定義)將決定例項化類的型別是 BoundedContinuous 還是 BoundedDiscrete。同樣適用於 Unbounded 類。請參閱這些類以獲取更多資訊。
類別型 |
||||
|---|---|---|---|---|
獨熱 |
多獨熱 |
類別型 |
多類別 |
二元 |
與 gymnasium 不同,TorchRL 沒有任意 specs 列表的概念。如果多個 specs 必須組合在一起,TorchRL 假設資料將以字典形式(更具體地說是 TensorDict 或相關格式)呈現。在這些情況下,相應的 TensorSpec 類是 Composite spec。
儘管如此,可以使用 stack() 將 specs 堆疊在一起:如果它們相同,它們的形狀將相應擴充套件。否則,將透過 Stacked 類建立惰性堆疊。
類似地,TensorSpecs 與 Tensor 和 TensorDict 具有一些共同行為:它們可以像常規 Tensor 例項一樣被重塑 (reshaped)、索引 (indexed)、壓縮 (squeezed)、解壓縮 (unsqueezed)、移動到另一個裝置 (to) 或解綁 (unbind)。
某些維度為 -1 的 Specs 被稱為“動態”Specs,負維度表示相應資料具有不一致的形狀。當被最佳化器或環境(例如,批次環境,如 ParallelEnv)看到時,這些負形狀告訴 TorchRL 避免使用緩衝區,因為張量形狀不可預測。
|
張量元資料容器的父類。 |
|
二元離散張量 Spec。 |
|
有界張量 Spec。 |
|
離散張量 Spec。 |
|
TensorSpec 的組合。 |
|
離散張量 Spec 的串聯。 |
|
獨熱離散張量 Spec 的串聯。 |
|
非張量資料的 Spec。 |
|
一維獨熱離散張量 Spec。 |
|
張量 Spec 堆疊的惰性表示。 |
|
複合 Spec 堆疊的惰性表示。 |
|
無界張量 Spec。 |
|
|
|
|
以下類已棄用,僅指向上面的類
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
已廢棄的 |
|
已廢棄的 |
樹和森林¶
TorchRL 提供了一套類和函式,可用於高效地表示樹和森林,這對於蒙特卡洛樹搜尋 (MCTS) 演算法特別有用。
TensorDictMap¶
MCTS API 的核心是 TensorDictMap,它就像一個儲存,其中索引可以是任何數值物件。在傳統儲存(例如 TensorStorage)中,只允許整數索引。
>>> storage = TensorStorage(...)
>>> data = storage[3]
TensorDictMap 允許我們在儲存中進行更高階的查詢。典型的例子是當我們有一個包含一組 MDPs 的儲存,並且我們想根據其初始觀測、動作對來重建軌跡。在張量術語中,這可以用以下虛擬碼來表示
>>> next_state = storage[observation, action]
(如果與此對關聯的下一個狀態不止一個,則可以返回一個 next_states 堆疊來代替)。這種 API 有意義,但會受到限制:允許由多個張量組成的觀測或動作可能難以實現。因此,我們提供一個包含這些值的 tensordict,並讓儲存知道要檢視哪些 in_keys 來查詢下一個狀態
>>> td = TensorDict(observation=observation, action=action)
>>> next_td = storage[td]
當然,這個類也允許我們用新資料擴充套件儲存
>>> storage[td] = next_state
這非常方便,因為它允許我們表示複雜的 rollout 結構,其中在給定節點(即給定觀測)採取了不同的動作。所有已觀測到的 (觀測, 動作) 對都可能引導我們獲得一組可進一步使用的 rollout。
MCTSForest¶
從初始觀測構建一棵樹就變成了如何高效組織資料的問題。MCTSForest 的核心有兩個儲存:第一個儲存將觀測連結到資料集歷史中遇到的動作的雜湊和索引
>>> data = TensorDict(observation=observation)
>>> metadata = forest.node_map[data]
>>> index = metadata["_index"]
其中 forest 是一個 MCTSForest 例項。然後,第二個儲存記錄與該觀測關聯的動作和結果
>>> next_data = forest.data_map[index]
next_data 條目可以有任何形狀,但通常會與 index 的形狀匹配(因為每個索引對應一個動作)。一旦獲得 next_data,就可以將其與 data 放在一起形成一組節點,並且可以對每個節點擴充套件樹。下圖展示了這是如何完成的。
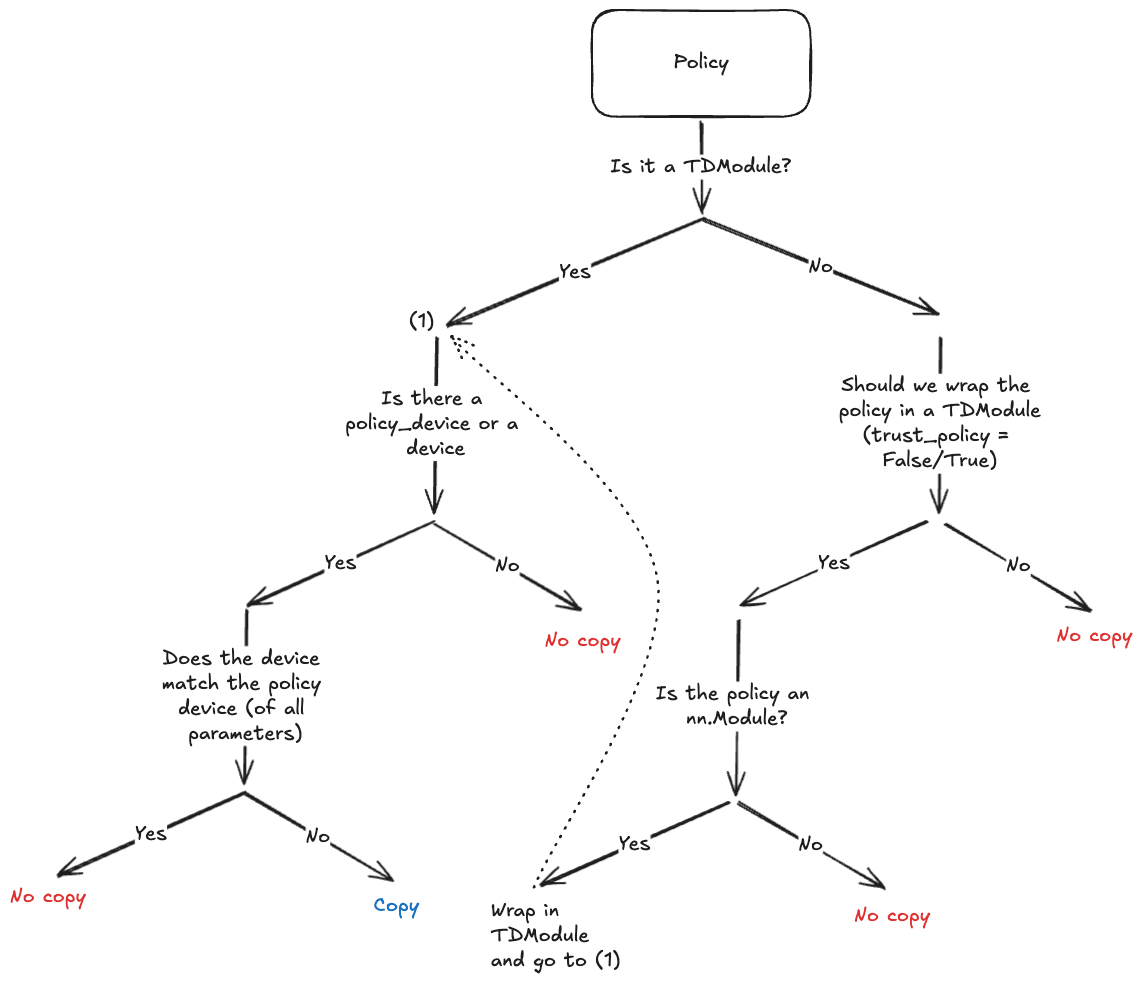
從 MCTSForest 物件構建一棵 Tree。流程圖表示從初始觀測 o 開始構建一棵樹。get_tree 方法將輸入資料結構(根節點)傳遞給 node_map TensorDictMap 例項,該例項返回一組雜湊和索引。然後使用這些索引來查詢與根節點相關的相應動作、下一個觀測、獎勵等元組。從中建立每個頂點(如果要求緊湊表示,可能會有更長的 rollout)。然後使用頂點堆疊進一步構建樹,這些頂點堆疊在一起構成根節點的分支。這個過程會重複給定的深度或直到樹無法再擴充套件為止。¶
|
一個將二進位制編碼張量轉換為十進位制的 Module。 |
將雜湊值轉換為可用於索引連續儲存的整數。 |
|
|
MCTS 樹的集合。 |
|
一個用於生成與儲存相容的索引的 Module。 |
|
一個將隨機投影與 SipHash 結合以獲得低維張量的 module,更容易透過 |
|
一個用於計算給定張量的 SipHash 值的 Module。 |
|
TensorDict 的 Map-Storage。 |
用於實現不同儲存的抽象。 |
|
|
人類反饋強化學習 (RLHF)¶
在人類反饋強化學習 (RLHF) 中,資料至關重要。鑑於這些技術常用於語言領域,而該領域在庫中的其他 RL 子領域中鮮有涉及,因此我們提供了專門的實用工具來促進與外部庫(如資料集)的互動。這些實用工具包括用於對資料進行分詞、以適合 TorchRL 模組的方式格式化資料以及最佳化儲存以實現高效取樣的工具。
|
|
|
|
|
用於 prompt 資料集的分詞配方。 |
|
|
|
一個用於使用因果語言模型執行 rollout 的類。 |
|
一個 Process Function 工廠,用於對文字示例應用 tokenizer。 |
|
載入分詞後的資料集,並快取其記憶體對映副本。 |
|
無限迴圈迭代一個 iterator。 |
|
建立一個數據集並從中返回一個 dataloader。 |
|
恆定 KL 控制器。 |
|
如 Ziegler 等人發表的論文 "Fine-Tuning Language Models from Human Preferences" 中所述的自適應 KL 控制器。 |
實用工具¶
|
多步獎勵轉換。 |
|
給定一個 TensorSpec,透過新增形狀為 0 的 spec 來移除專屬鍵。 |
|
給定一個 TensorSpec,如果不存在專屬鍵則返回 true。 |
|
如果 spec 包含延遲堆疊的 spec 則返回 true。 |
|
將巢狀 tensordict(其中每一行都是一個軌跡)轉換為 TED 格式。 |
|
一個儲存載入鉤子,用於將展平的 TED 資料反序列化為 TED 格式。 |
將持久化 tensordict 中的軌跡組合成一個儲存在檔案系統中的單一 standing tensordict。 |
|
|
將使用 TED2Nested 準備的資料集分割成一個 TensorDict,其中每個軌跡都作為其父巢狀張量的檢視儲存。 |
|
一個儲存儲存鉤子,用於將 TED 資料序列化為緊湊格式。 |
|
將 TED 格式的資料集轉換為填充了巢狀張量的 tensordict,其中每一行都是一個軌跡。 |
|
ReplayBuffer 的 MultiStep 轉換。 |
