Wav2Vec2ASRBundle¶
- class torchaudio.pipelines.Wav2Vec2ASRBundle[source]¶
一個數據類,捆綁了使用預訓練的
Wav2Vec2Model所需的相關資訊。此類提供了用於例項化預訓練模型的介面,以及檢索預訓練權重和模型所需額外資料的必要資訊。
Torchaudio 庫例項化此類的物件,每個物件代表一個不同的預訓練模型。客戶端程式碼應透過這些例項訪問預訓練模型。
請參閱下方瞭解用法和可用值。
- 示例 - ASR
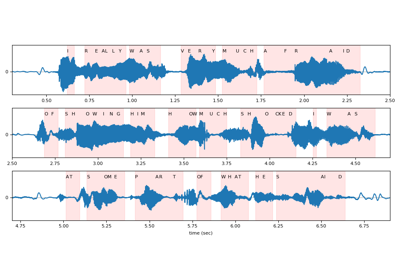
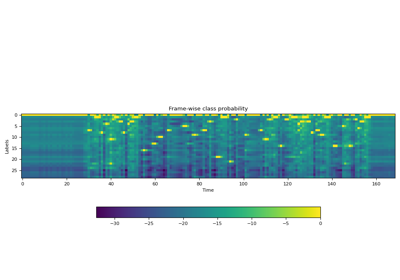
>>> import torchaudio >>> >>> bundle = torchaudio.pipelines.HUBERT_ASR_LARGE >>> >>> # Build the model and load pretrained weight. >>> model = bundle.get_model() Downloading: 100%|███████████████████████████████| 1.18G/1.18G [00:17<00:00, 73.8MB/s] >>> >>> # Check the corresponding labels of the output. >>> labels = bundle.get_labels() >>> print(labels) ('-', '|', 'E', 'T', 'A', 'O', 'N', 'I', 'H', 'S', 'R', 'D', 'L', 'U', 'M', 'W', 'C', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', "'", 'X', 'J', 'Q', 'Z') >>> >>> # Resample audio to the expected sampling rate >>> waveform = torchaudio.functional.resample(waveform, sample_rate, bundle.sample_rate) >>> >>> # Infer the label probability distribution >>> emissions, _ = model(waveform) >>> >>> # Pass emission to decoder >>> # `ctc_decode` is for illustration purpose only >>> transcripts = ctc_decode(emissions, labels)
- 使用
Wav2Vec2ASRBundle的教程
屬性¶
sample_rate¶
方法¶
get_labels¶
- Wav2Vec2ASRBundle.get_labels(*, blank: str = '-') Tuple[str, ...][source]¶
輸出類別標籤。
第一個是空白標記,它是可定製的。
- 示例
>>> from torchaudio.pipelines import HUBERT_ASR_LARGE as bundle >>> bundle.get_labels() ('-', '|', 'E', 'T', 'A', 'O', 'N', 'I', 'H', 'S', 'R', 'D', 'L', 'U', 'M', 'W', 'C', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', "'", 'X', 'J', 'Q', 'Z')
get_model¶
- Wav2Vec2ASRBundle.get_model(*, dl_kwargs=None) Module¶
構造模型並載入預訓練權重。
權重檔案將從網際網路下載,並使用
torch.hub.load_state_dict_from_url()進行快取- 引數:
dl_kwargs (關鍵字引數字典) – 傳遞給
torch.hub.load_state_dict_from_url()。- 返回值:
Wav2Vec2Model的變體。對於下面列出的模型,對輸入執行額外的層歸一化。
對於所有其他模型,返回一個
Wav2Vec2Model例項。WAV2VEC2_LARGE_LV60K
WAV2VEC2_ASR_LARGE_LV60K_10M
WAV2VEC2_ASR_LARGE_LV60K_100H
WAV2VEC2_ASR_LARGE_LV60K_960H
WAV2VEC2_XLSR53
WAV2VEC2_XLSR_300M
WAV2VEC2_XLSR_1B
WAV2VEC2_XLSR_2B
HUBERT_LARGE
HUBERT_XLARGE
HUBERT_ASR_LARGE
HUBERT_ASR_XLARGE
WAVLM_LARGE
